Externalization of a Flink state to Aerospike
At Contentsquare, we’re happy to leverage Apache Flink as a key technology to deliver high-throughput, low-latency and high resiliency stateful streaming. However, despite remaining extremely reliable, it has started showing signs of distress due to our demanding use cases. This article focuses on the process of externalizing one of the RocksDB-embedded states from our Flink application to an external database, as well as the motivations that led to this decision. It can be also seen as the eleventh Flink’s gotcha in addition to the ten we shared in a previous article.
Background
Flink represents an essential component of our pipeline. Each of our jobs processes tens of thousands of messages per second applying a multitude of filters, transformations and aggregations. Flink fits into a multi-cloud Kubernetes-hosted environment, where the biggest cluster counts several dozen nodes. Its role, and where it finds its place in our data pipeline, can be depicted in the diagram below.
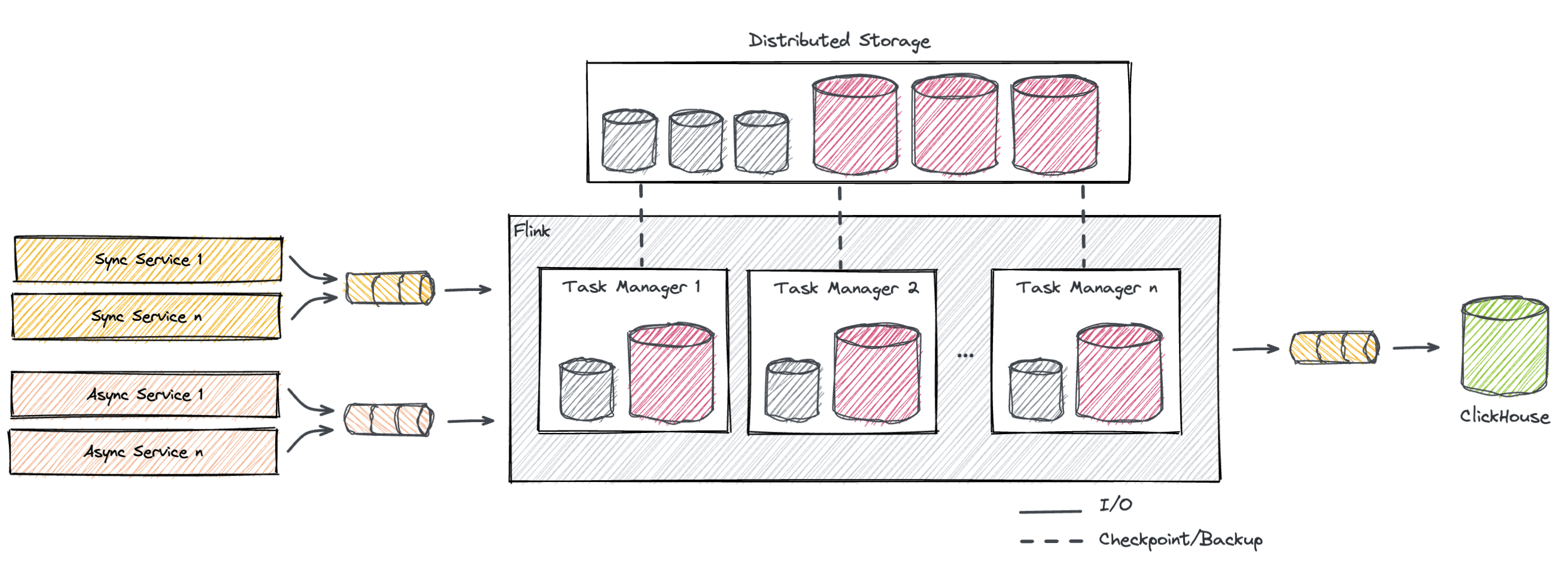
In a nutshell, the Flink cluster runs a single streaming job which implements what we call Sessionization, meaning the aggregation of multiple events in a time-based manner, which essentially represent a single user activity. We consider a session closed after 30 minutes of inactivity. This means that, if belonging events keep arriving in shorter time spans, a session can technically stay open for hours. These sessions eventually get their way into our data warehouse, ClickHouse, where most of the data analysis takes place.
Flink consumes data from a number of Kafka topics which serve as a sink for a bunch of producer services. Some of these, so-called sync services, continuously forward traffic originated by our client’s applications and websites, while others, the async services, produce events coming from other sources. Async events are yet bound to the sync data, but they can arrive up to a whole week after the session closure. The idea here is to use Flink as a reconciliation service: if the async events arrive while the window is open, they enrich the ongoing session. On the other hand, if they come afterwards, they trigger an update on ClickHouse.
As you can guess, the job is doubly stateful. The session window, by its nature, continuously accumulates messages, which naturally translates into a state, referred to as session state. Also, to accommodate the above-mentioned async events, there is a need for a second, much larger state which we will call history state.
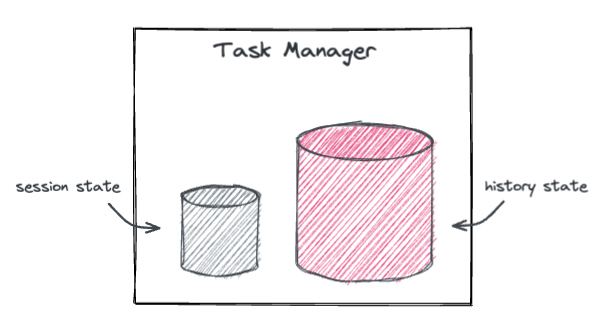
Both states are hosted on RocksDB via its Flink state backend that keeps data in database instances locally to the nodes, while no replication is enforced. In fact, Flink implements resiliency by regularly persisting states in a distributed storage system to ensure consistent failure recovery.
Where the problem is (bigger is not always better)
As already mentioned, async services can produce updates up to a week after the related sync events have been produced, which essentially means that sync data has to be kept in the history state for at least that amount of time. Not surprisingly, this state can grow big, as big as several terabytes per job in our case.
Even though Flink handles its state quite seamlessly, multiple issues do arise when the size of it gets significant. Below are just a few of these problems that prompted us to find a solution:
Slow restarts
When any Flink task manager restarts, it downloads the full checkpoint back to the disk to rebuild its own state. During this time an important amount of disk & network I/O gets generated, and no output gets produced.
Slow scaling
As part of a horizontal scaling operation, the parallelism factor gets increased/decreased accordingly. In these cases, task managers shuffle the data among them which leads to a relevant amount of network IO. During this time, an effective interruption of service occurs, which, in worst cases, can last hours.
Slow checkpoint operations
As mentioned previously, the state regularly gets backed up by Flink in a distributed storage system. During this period, since we use aligned checkpoints, the job ends up applying back pressure if the process drags on. It goes without saying that a large state is equal to longer operations. In fact, we have experienced checkpoint durations of over 30 minutes. A partial improvement to that, was represented by incremental checkpoints, which however have other collateral effects (see next point).
Checkpoint persistence cost
Storing numerous and large checkpoints into a distributed storage system represents a non-negligible cost. The introduction of incremental checkpoints does reduce the size of each individual checkpoint file. However, every checkpoint does not represent a self-contained state, and we can easily end up with countless files, with a tendency to grow and the impossibility to apply an effective retention policy.
State retention time rigidity
Varying the history state retention time to accommodate business needs represents a very invasive operation. In fact, a greater retention time means greater storage capacity. Our cluster is currently composed of instances with embedded NVMe disks. For these reasons, upscaling would require replacing these by larger machines. Horizontal scaling is not an option here. In fact, we would implicitly add CPU and memory for the sole sake of storage capacity.
How do we fix this?
The main idea is to simply get the history state out of Flink, which, on its part, frees itself from the biggest state. Doing so, most of the issues mentioned above would be significantly mitigated.
However, despite sounding like the ultimate solution, it comes with a main drawback: in fact, state handling provided by the Flink framework gets lost.
Out of the box, Flink only supports two state backends: HashMapStateBackend and EmbeddedRocksDBStateBackend. Translated: any aspect related to the interaction with the state will be manually handled by custom code: access, error handling, serialization etc. Not to mention the conception and maintenance of a whole new component infrastructure.
The new architecture would look like this:
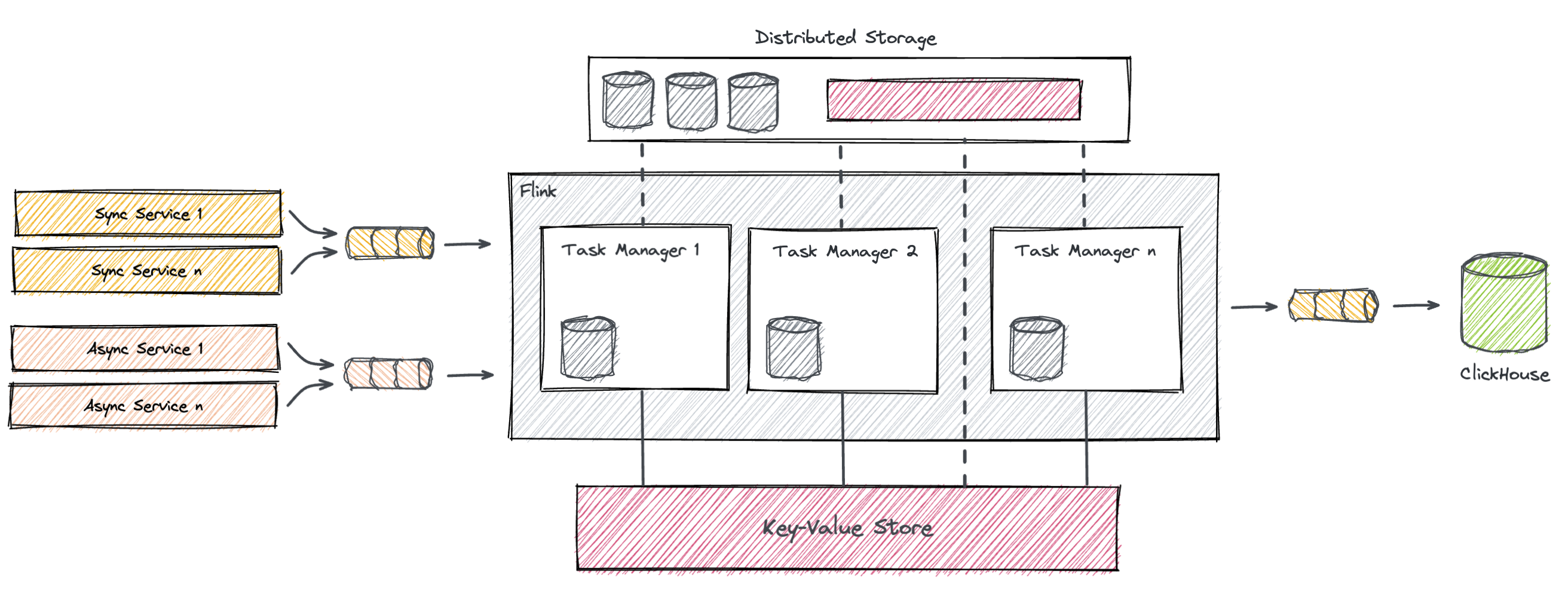
The main ingredients for an effective design include the deployment of a reliable persistent key-value store accessible from the Flink cluster. This database needs to be highly resilient, implement failover strategies and apply replication to its content. It also needs to be blazing fast on inserts and updates, mostly because it will be called synchronously, in order to preserve Flink’s delivery semantics. Also, the content of the store has to be backed up regularly. This allows us to recover from failures, similarly to the process of restoring from a checkpoint. Finally, a TTL of seven days will be set, which effectively represents the state retention.
There are many key-value stores out there that potentially meet these requirements, but after careful considerations, we selected Aerospike Database. The choice fell on it, mostly because of its sub-millisecond latencies at very high throughput, replication capabilities and a rich SQL-resembling query language named AQL. Aerospike is also used in several other services across our stack, and we have acquired a certain degree of expertise, which also led us to the final choice.
Let’s get our hands dirty
In this section, we will go through the most indicative points regarding the implementation of the solution described above.
State usage
Firstly, we need to define how to interact with an external state while replacing the RocksDB-embedded implementation. The following code shows a very minimal interface for a key-value store client.
trait ExternalStateRepository[K, V] { def put(k: K, v: V): Try[Unit] def get(k: K): Try[V] def close(): Unit = {}}The implementation is quite straightforward: firstly, we implement get and put logic by using com.aerospike.client.AerospikeClient, the Aerospike reactive synchronous client. Then, we apply some retry strategy with a constant backoff. If an operation fails, we retry it for a finite amount of times, eventually causing the termination of the job.
override def put(key: String, value: Array[Byte]): Try[Unit] = {
val asKey = buildKey(key) val asBin = new Bin(config.binName, value)
measureRecordSize(asBin) metrics.incCounter(MetricsEnum.statePut)
val (result, duration) = PerfUtils.time { Retry( () => Try(aerospikeClient.put(writePolicy, asKey, asBin)), config.retryBackoffMs, config.maxRetries ) }
metrics.histogram(MetricsEnum.statePutLatency, duration) result
}Both operations get executed in a ProcessWindowFunction and must be synchronous. A future improvement would be the usage of Flink Async I/O which would lift this restriction.
Data Compression
Although Aerospike has the capability to apply a layer of compression on stored data, we decided to do it client side instead to avoid sending uncompressed data over the network. Our pick was ZSTD: a fast compression algorithm with an excellent compression ratio.
Aerospike cluster infrastructure
The biggest Aerospike cluster is composed of six instances with 12 CPUs and 96 GB of memory. Data is naturally persisted in their 7.5 TB NVMe SSDs, with a replication factor of 2.
Another relevant configuration is write-block-size of 4 MB, which is based on the grounds that the largest storable record never exceeds that size. Despite most of the records weigh a few kilobytes on average, this high value did not cause any performance issue. Finally, high-water-disk-pct to 65% was found to be a satisfactory value, with an increase of defrag-lwm-pct to 60%.
Key metrics
Our external state easily becomes a sensitive point in the pipeline, and, as such, it is essential to introduce a whole series of new metrics to keep the situation monitored. Important metrics include writes, read hits/misses, latencies, retries, failures as well as the estimated size of the records on write.

On top of that, a solid layer of alerting has been put in place, especially for what concerns the health of the Aerospike cluster. For instance, the most important indicator is the disk usage in relation to the high water mark value. Data eviction in fact, starts once that limit gets breached.
Deduplication
Another important subject that came out in this phase is the need of a deduplication step. In fact, in case of a sudden crash, while Flink nodes rebuild their states from the last checkpoint, the external state still retains up-to-date data. This misalignment can cause significant inconsistencies and to avoid them, a deduplication phase has been implemented by leveraging dedicated unique identifiers.
Testing
As any other migration task, the testing phase is essential. Apart from a good test coverage, there is another measure that we had to put in place in order to ensure no functional regression has been introduced.
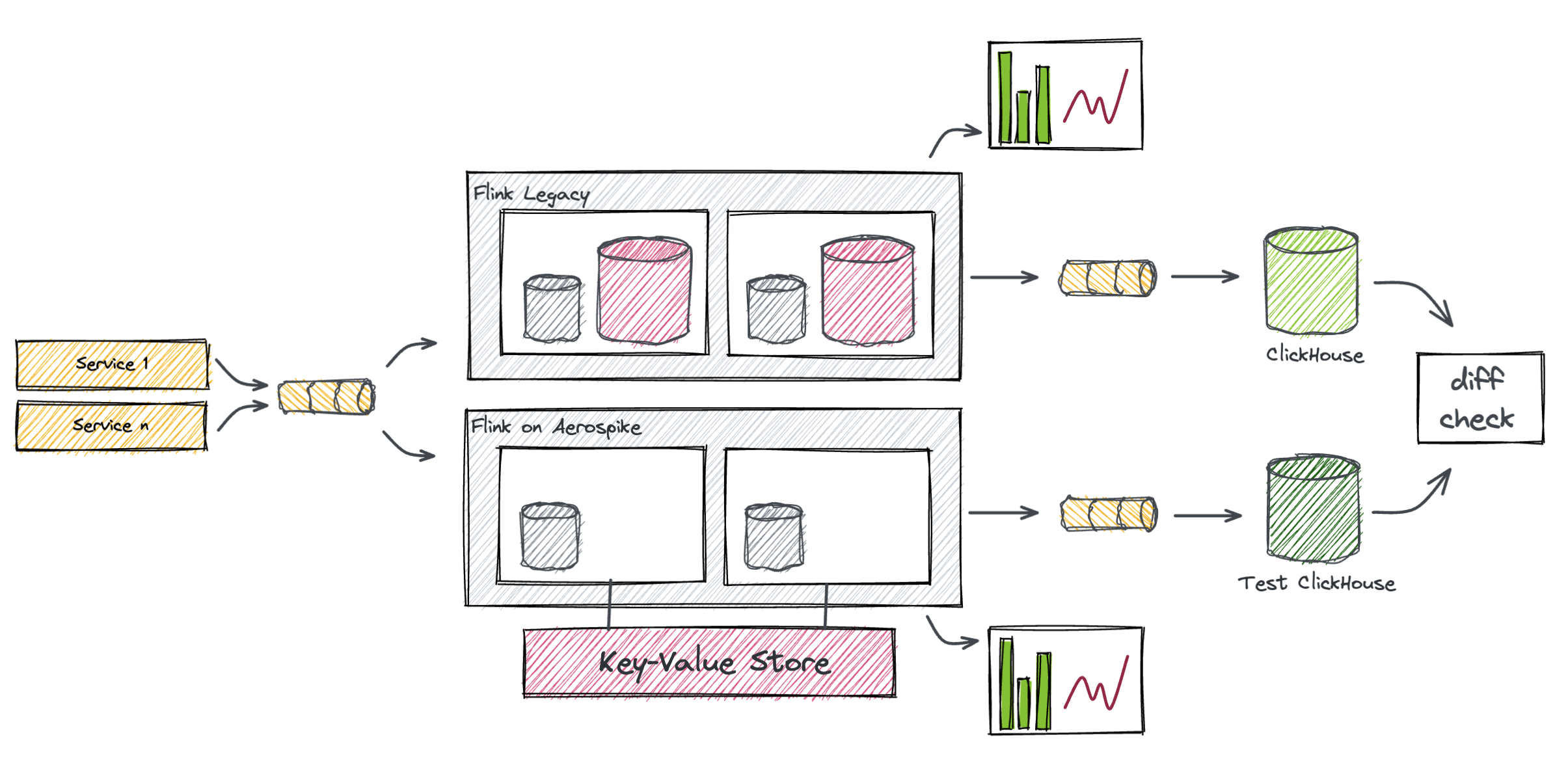
Validation has been achieved by flanking a second, Aerospike-based Flink cluster next to the one operating on pre-prod, which then produces into a dedicated ClickHouse. In this environment we ingest only a fraction of the production traffic, but we made sure that data was sufficient to validate the job functionality. At this point we’re finally ready to perform a series of checks: firstly comparing the outputs of the two ClickHouses, then verifying a bunch of key metrics (including those introduced for the purpose).
Deployment Model
Changing the state of a stateful application and deploying it with zero downtime is certainly not trivial, hence the brainy deployment model.
First, side run it…
Similarly to what has been done in the testing phase, the first step is to deploy the new cluster side-by-side to the production one. The new job consumes from the same topics the legacy job does, and writes into a dead-letter topic. Ultimately, the goal here is to fill up the new state until it’s aligned with the legacy state. This process takes 7 days, at the end of which, the TTL kicks in and the first entries start to expire.
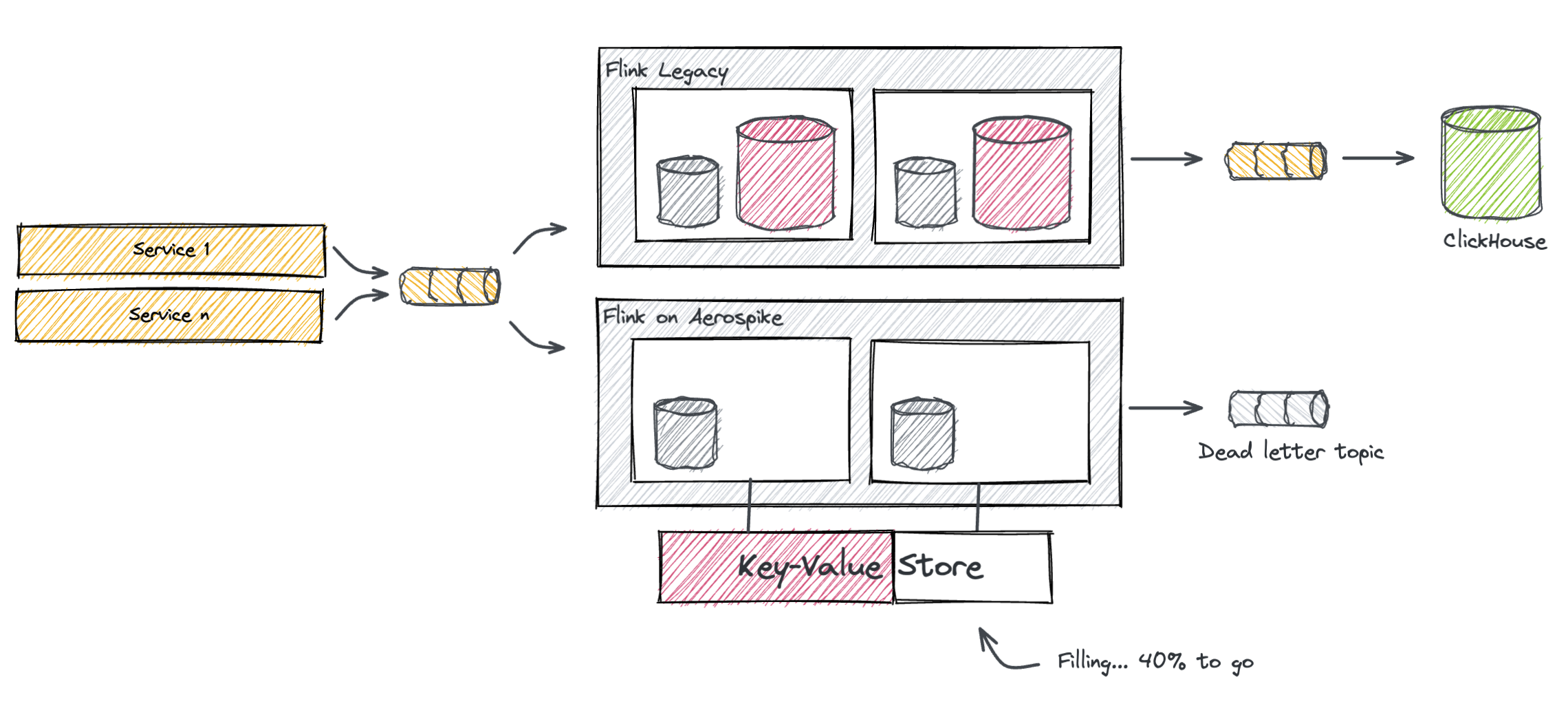
During this time we check the metrics of the two clusters regularly and make sure they look identical. It is also the occasion to do some fine-tuning to the infrastructure.
…then, plug it in!
When the wait time is over we proceed with the actual deployment. Essentially, now that the new state is heated up, the new job is ready to produce its outputs in the production topic, while the legacy job can be finally shut down.
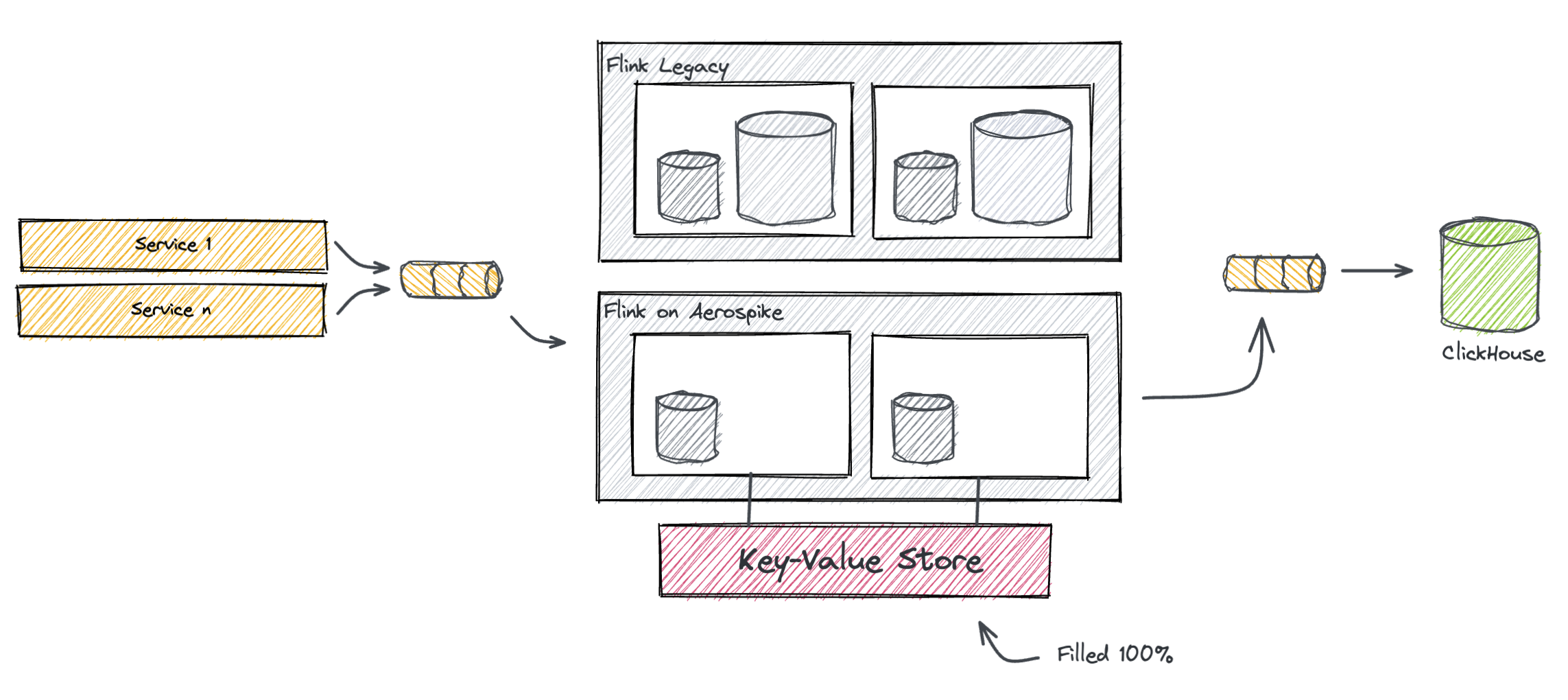
This is the step-by-step process in detail:
- Stop the producer services (lag will be accumulated back on the topic they consume from)
- Wait that both clusters have consumed the remaining data in the pipes
- Stop both jobs
- Restart the new job only, by switching its destination topic from dead-letter to production (this can be made by a simple configuration change)
- Restart the producer services
After a thorough verification, the old cluster can be finally decommissioned and the migration can be considered as completed.
Findings
Following the deployment we have noted a whole set of improvements, some of which will be discussed in this chapter.
Faster restarts
The first achievement is ending up with the generation of much smaller checkpoints, which, in one of our environments, has even seen a sensible drop of 81%.
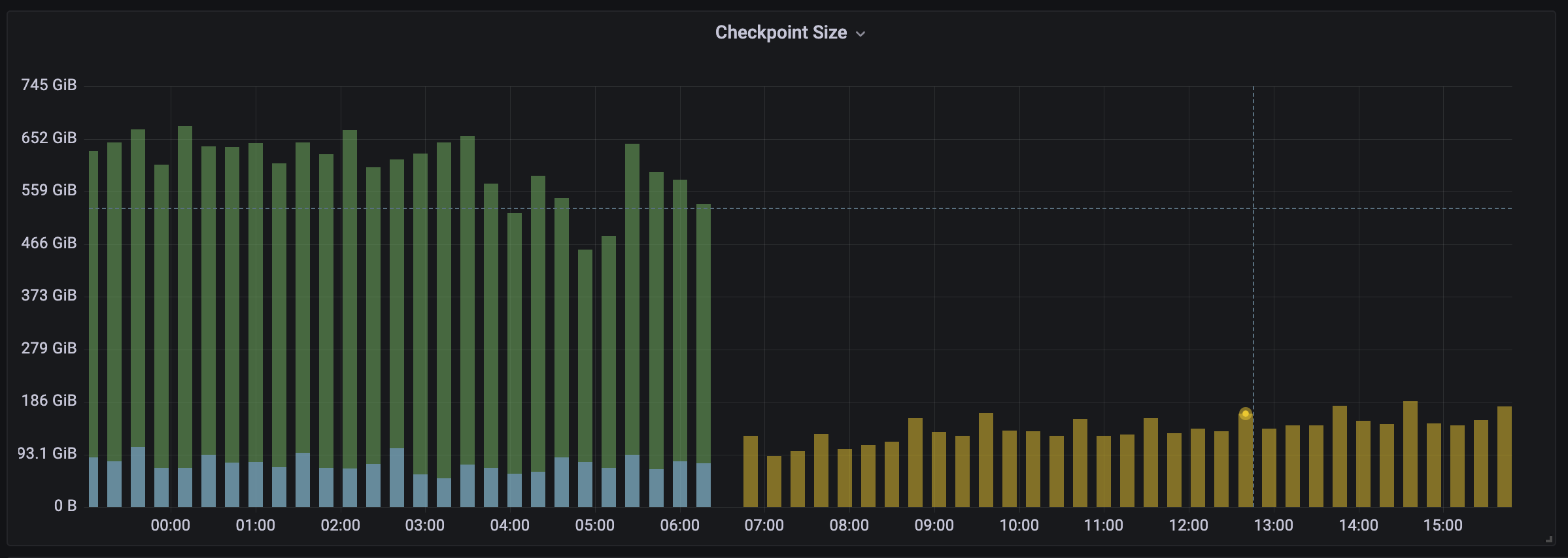
Thanks to that, checkpointing time, and consequently the nodes’ restart time have been reduced significantly (by over 60% in some cases), finally making routine operations such as deployments and scaling much quicker.
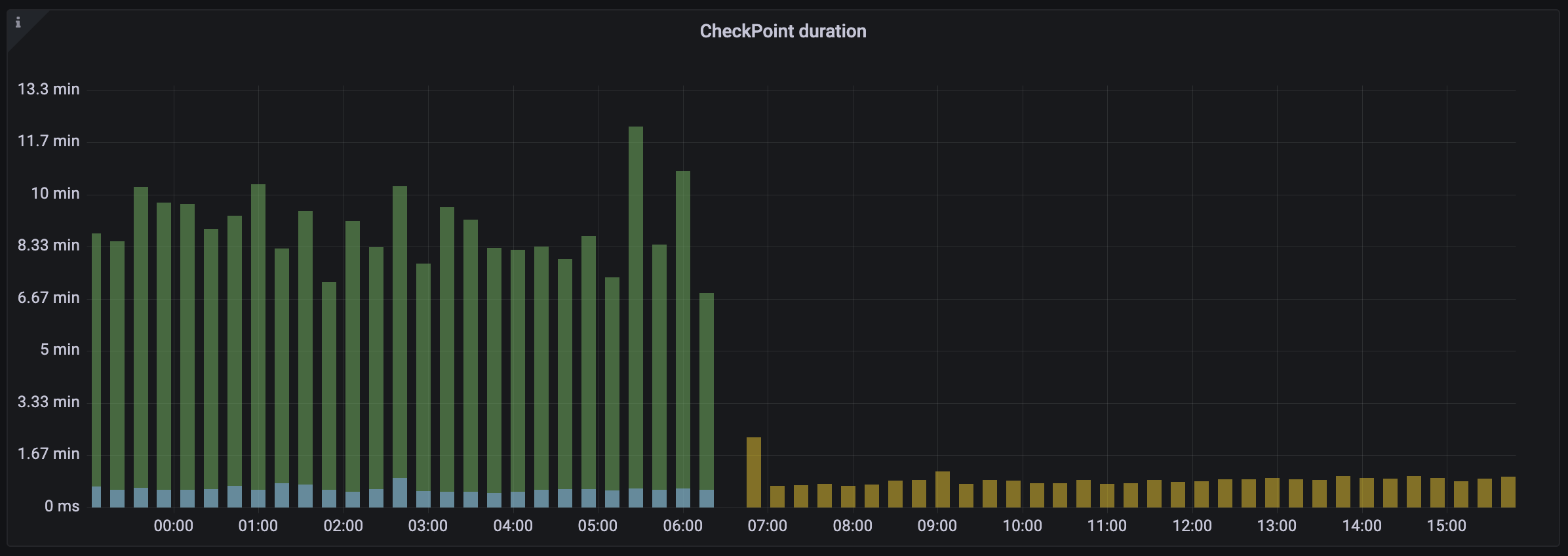
Bye bye incremental checkpoints
As already mentioned, we could finally switch back to non-incremental checkpoints. Checkpoint files are now self-contained, and we can now afford to keep only a small number of them in the distributed storage. This results in a huge cost saving.
Data retention flexibility
Data retention time can now be changed easily by scaling out the Aerospike cluster and adjusting the TTL accordingly. The job restart is not necessary.
Flink cluster shrinking
Last but not least, one of the biggest improvements was being able to afford a massive down scale of our Flink clusters. Getting rid of a large state means that task managers persist much fewer data. As an example, on AWS, we have migrated from i3.2xlarge instances to r5d.2xlarge which feature a smaller disk. But most importantly, we managed to cut in half the cluster size: from 40 nodes down to 20. These measures have resulted in a massive saving of about 60%.
Conclusion
As we have seen, the externalization of the history state onto Aerospike has brought us tons of benefits. At the time of writing, our Flink jobs have been running for months and no major issue has ever occurred. Although the Flink documentation sets some guidelines on how to deal with large states, in some cases, there is little room for improvement and more radical interventions are required. Hopefully, this article will come to the rescue, and serve as inspiration in such cases.
Special thanks to Robin Cassan for leading the project, and all the engineers who participated in the writing of this article: Pawel Gontarz, Pierre Lesesvre, Yang Li, Elsa Donovan, Jonathan Meyer, François Violette and Thomas Griozel.