Handling Black Friday at scale
Over the past few years, Black Friday and Cyber Monday have grown to become the busiest days of the year for most online retailers.
Contentsquare is in a unique position to witness this huge traffic spike because we help 500+ of the top retailer websites analyze the behavior of their visitors and optimize their journey.
However from an engineering perspective, what we experience is more akin to a coordinated DDoS attack… The good news is that contrary to most attacks, we know exactly when it will happen and we can prepare accordingly!
This time, we thought it would be interesting to publicly share some metrics about the traffic spike we handled in 2020, and a few lessons we have learned over the years to sail through this event successfully.
Looking at our Black Friday traffic spike
First, a few details about our infrastructure:
- Our JavaScript tag is embedded in our customer websites and is sending us batches of events, which we later process in a complex analytics pipeline.
- For a single pageview, there can be multiple batches of events, meaning multiple requests to our analytics endpoint.
- Our data pipeline is deployed in two main regions: U.S. and Europe. We aggregated them together in the numbers below.
Here is what the daily number of pageviews, aggregated over all our customers, looked like in 2020 compared to 2019:
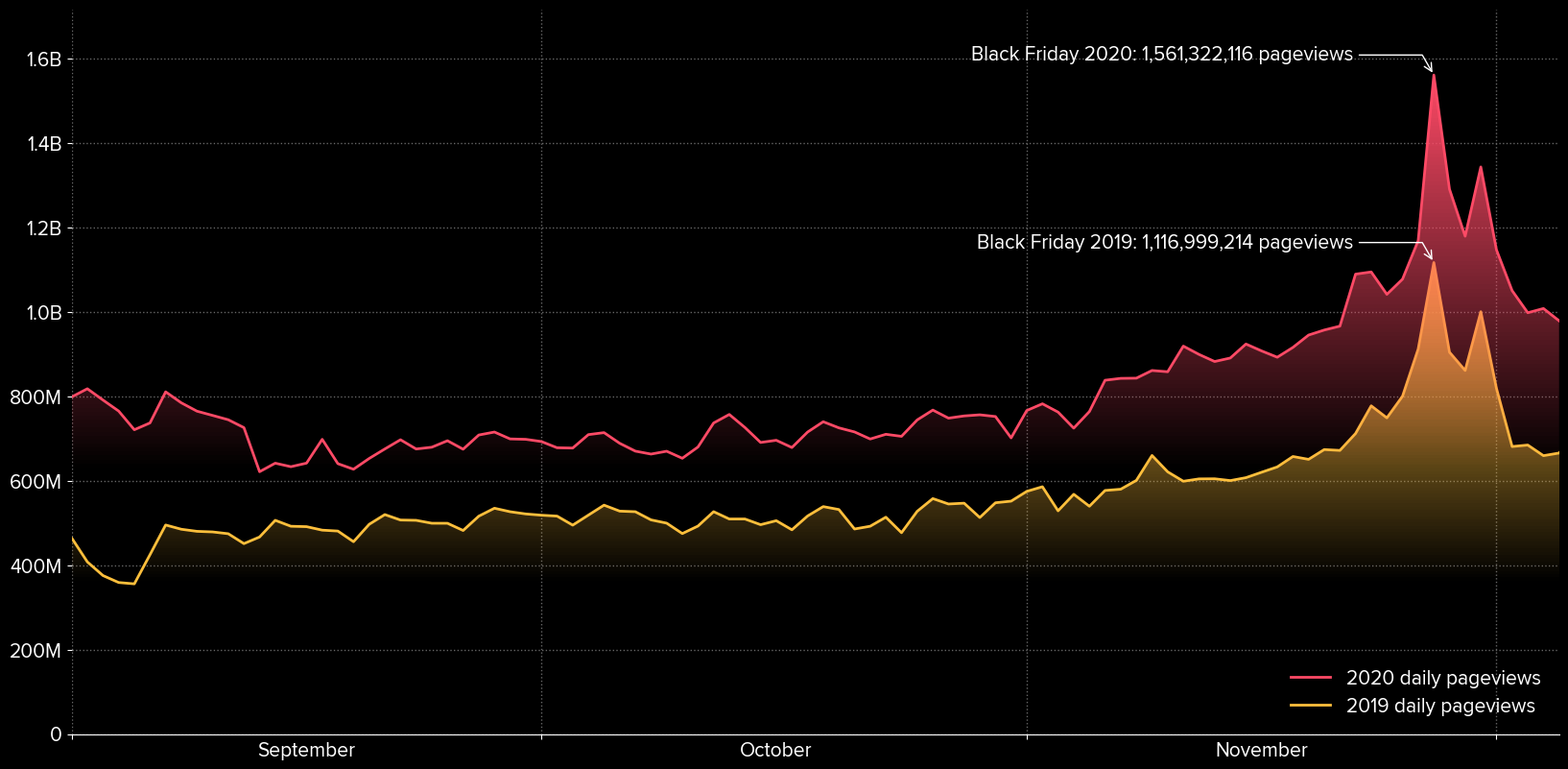
As you can see, the amount of daily pageviews we track, usually hovering around 700 million, increased more than twofold up until November 27, reaching a staggering 1.56 billion!
Looking closer at the requests sent to our analytics endpoints (excluding the JS tag itself which is statically served from a CDN), we reached an all-time high of 256,163 requests per second on average between 19:30 and 20:00 UTC on November 27:
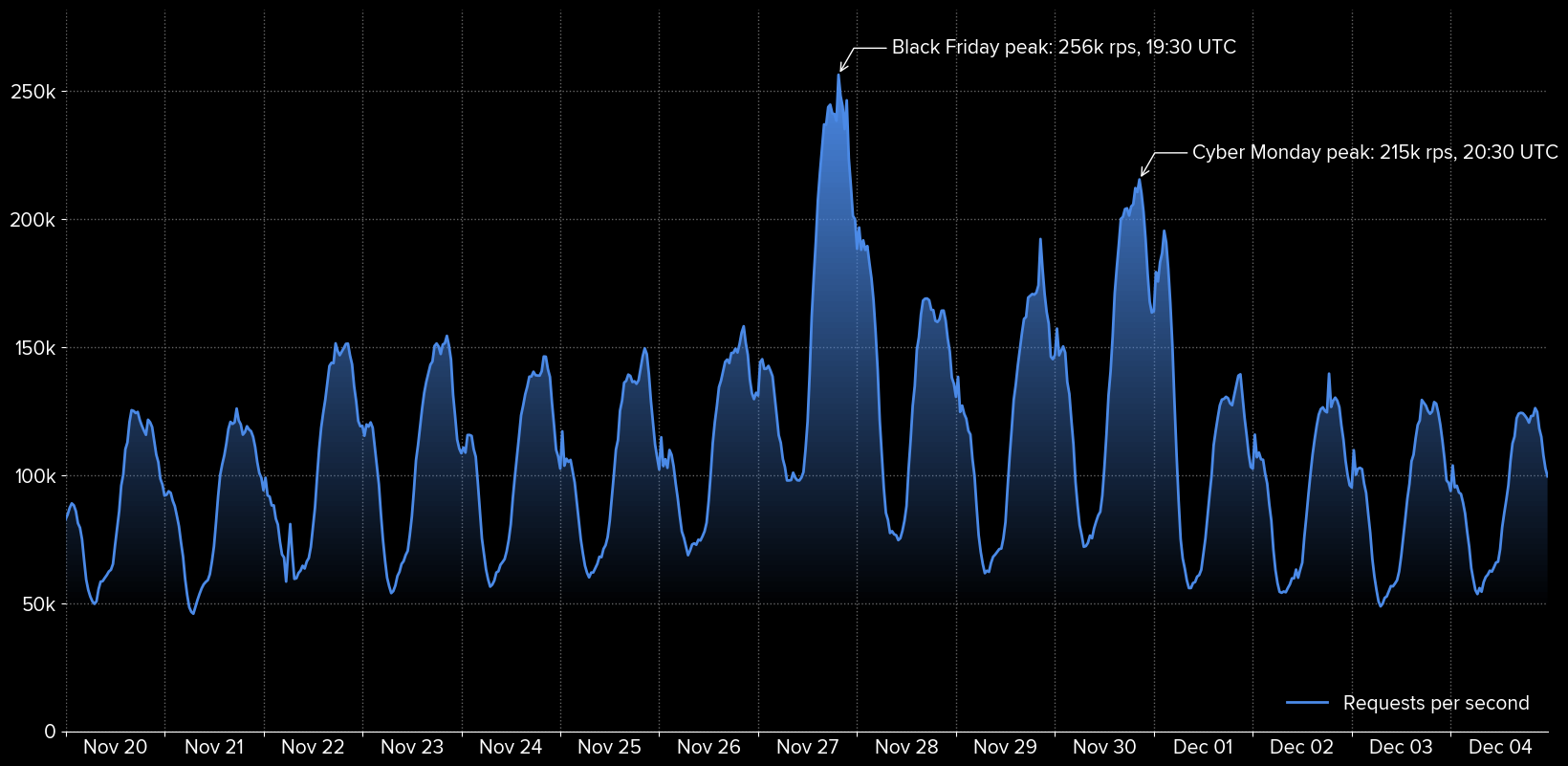
Another way to look at these numbers: during the 4 days spanning from Nov 27 to Dec 01, we processed over 49 billion requests!
Some lessons we learned over the years
Code freeze
As confident as we are in our automated testing, we still don’t want to risk introducing new bugs or performance regressions in production at such a critical time. That is why we declare a company-wide code freeze, starting a few days before Black Friday until the day after Cyber Monday.
It means that even though developers can obviously continue working on new features, we forbid the deployment of any new code in production, unless it is a critical bug fix that went through code review by multiple senior developers.
One usual side-effect to be aware of: many teams will try to ship features just before the code freeze, which could actually make the platform less stable because of the sheer amount of relatively new code being deployed at the same time. This is why it is important to involve all teams in holiday preparedness so they can plan ahead and be mindful of the aggregated risk.
Benchmark and investigate bottlenecks aggressively
The overall throughput and latency of our pipeline will always be limited by its slowest component. It would be useless to scale up our endpoint servers if our Kafka cluster down the line can’t accept writes fast enough.
To find these bottlenecks before they are reached, one must of course run benchmarks and load tests. Those can be quite time consuming and the cost of a temporarily scaled up copy of the production environment can be very significant, but they are well worth it if they help avoid a future service disruption.
We actually run 2 different kinds of benchmarks:
- Defensive benchmarks, usually a month before events like Black Friday, to test the scalability of our current infrastructure.
- Design benchmarks, which we can do up to a year in advance, to test major evolutions of our architecture before committing to them.
Monitor continuously
This seems rather obvious nowadays, but having full observability of critical metrics across the infrastructure is a must, even more so in planned events where they will significantly deviate from the baseline.
Being a provider of analytics ourselves, it should not be surprising that we love to dig into our infrastructure metrics and try to explain sudden changes. On one occasion, it took a few minutes of investigation following a critical alert to realize that it was actually a false positive caused by one of our largest customers which website went completely down!
Avoid instance starvation
Autoscaling is a must to handle sudden traffic spikes, but it is far from a magical solution. After all, even if sometimes it doesn’t feel this way anymore, there is still real hardware behind our virtualized instances.
At some point, even the largest of cloud providers can actually run out of physical servers to run workloads if all their customers are seeing a coordinated traffic increase like Black Friday. This is even more likely to happen when requesting specific instance types in specific regions, or when using spot instances.
The only solution is to plan ahead and reserve instances for critical services.
Capacity planning
If you need to reserve instances or if there are still components in the infrastructure that do not scale automatically, there needs to be some prediction of the expected load in order to add capacity in advance. How to do that without a crystal ball at hand?
We have a 3-step strategy for trying to estimate how big the increase will be:
- First, reach out to our top 50 customers and get their own predictions. This has the added benefit of being able to adjust their platform usage credits in advance if they would fall short of their quota. No surprises for anyone. And overall it is the kind of great, proactive customer service we are aiming for!
- Then, build our own global prediction based on top customers, historical trends and team opinions. The size of the safety margin should be correlated to the target SLA, which in our case is very high.
- Finally, be aware of the global context! Because of COVID-19 this year’s holiday season is very unusual and unpredictable. Some countries like France even postponed Black Friday by a full week for sanitary reasons.
If you look at the graphs above, you will see that the increase in traffic in the weeks leading to Black Friday was actually quite noticeable, which definitely informed our estimations.
Build strong relationships with cloud providers
Past a certain scale, the idea of self-service cloud providers does not make sense anymore. Given the footprint and the SLA of our infrastructure, we really benefit from having a clear communication channel with our providers of choice.
With priority support, we can deal efficiently with issues like raising service quotas, investigating obscure edge cases and getting operational advice.
Some providers even have dedicated event management programs that can be a great resource for planning and operations of specific events.
Prepare for the worst
Preparedness is about both taking necessary precautions and knowing how to react if despite them an incident still occurs.
We spend quite a lot of time debating doomsday scenarios for our infrastructure. Besides being fun and lively brainstorming sessions, we learn a lot by simulating every failure mode we can think of. For each of them, we prepare mitigation and escalation procedures even if we hope they will never be used!
For instance, if as mentioned above we fail to allocate new instances from our cloud providers, we have a strategy for prioritizing critical services by stealing capacity from less impactful ones. This is the kind of radical solution that would be a big stress factor if it needed to be discussed while an incident is ongoing!
Looking ahead
We expect our growth in terms of both customers and features to be so strong in the next few quarters that the peak traffic we experienced this year will soon become our new usual baseline!
Our wish for Black Friday 2021?
Be record-shattering again, exciting to prepare … but ultimately boring :-)

Thanks to Doron Hoffman, Koby Holzer, Olivier Devoisin and Raphaël Mazelier for contributing ideas and reviewing drafts of this!