Designing and optimizing Golissimo, our tool for building generic Kafka pipelines
At Contentsquare, we receive billions of events every day from our customer’s websites and native apps. These events are fed into our real-time data pipeline to be processed, aggregated and ultimately queried by our user-facing product lines.
This global pipeline is built on top of Apache Kafka which provides a fault-resilient, horizontally scalable buffering mechanism between our services, spanning multiple public clouds and regions.
Over time, throughout outages and regular operations like customer migrations, we found we had a recurring need to route and transform messages in an easily configurable way. Specifically, we wanted to be able to:
- Filter and copy messages from one Kafka topic to another, potentially between different regions, with filtering based on dynamic state accessible from internal APIs.
- Re-route messages arriving in a region which is not their target processing/storage region initially defined by each customer (we use TCP geo-routing for incoming connections).
- Replicate some of our data on multiple regions and environments.
- Benchmark and load-test our services and Kafka instances with production-like data.
- Minimize network traffic by mutualizing Kafka readers, where possible.
To answer these needs, we built an internal service called Golissimo (Colissimo is a popular parcel delivery service in France). Its main mission is to distribute a graph of Kafka message pipelines on multiple clouds, environments and regions.
This article will focus on its design and explain some of the insights we discovered while writing and optimizing its next major version.
Humble beginnings
The first version of Golissimo was actually one of the first Go programs we pushed to production, at a time when our infrastructure was much smaller in terms of scale and complexity. Back then, it didn’t make much sense to invest in generic data pipelines or operational efficiency.
As we grew, we started to face some issues:
- A single instance of Golissimo could only handle one data stream, which became inefficient both in CI and at runtime as we reached 30+ different deployments.
- Monitoring was difficult because we had one dedicated dashboard per deployment.
- We couldn’t use dynamic data for message filtering, so we had to manually reconfigure and redeploy frequently.
- We were using Kafka’s consumer auto-commit mode, which could lead to message loss in hard shutdowns.
Overall, we lacked the configurability, modularity and scalability required to operate an ever-growing number of pipelines in production.
Designing Golissimo v2
Engineering principles
We wanted our next major version to be a modern, cloud-native Go program: it should be Kubernetes-friendly and facilitate operations for our engineers through a single standalone binary. Luckily, Golissimo’s workload is mostly stateless because its data sources are Kafka topics and it doesn’t perform aggregations itself.
Its code should be modular, easily maintainable and extensible, to be as future-proof as possible. For instance, multiple data formats should be supported through reusable modules.
Last but not least, we aimed to save costs through improved performance and efficiency.
Architecture
A typical Golissimo pipeline looks like this:

As you can see, Golissimo is not limited to Kafka topics, it can also interface with files and REST APIs, making it a flexible and versatile data engineering tool.
Another important feature of Golissimo that sets if apart from most of our other services is that it acts as a single global deployment. Indeed, almost all our components are deployed and configured differently for each region and environment (production, staging, dev) that they run in, but Golissimo stands out as the rare component that needs to communicate across those boundaries.

When a Golissimo instance is starting up, it checks in which region and environment it is deployed, then selects from the global configuration the subset of pipelines it needs to run. The default rule we chose to attribute pipelines to instances is simple and deterministic: an instance will only run the pipelines that have their data source in its own region and environment.
Configuration
Having a single deployment means that we can have a single configuration file, which simplifies the whole system.
We considered various configuration formats and settled on HCL because it’s a battle-tested text format that was already familiar to the many developers using Terraform at Contentsquare.
This configuration file allows us to specify:
- Named data endpoints like Kafka topics, which can be sources or sinks in pipelines.
- Data pipelines which contain a source, a sink and the list of processing stages together with their configuration.
- High-level constructs to support bidirectional pipelines and more complex use cases.
The first version of Golissimo required the user to provide a lot of parameters for each pipeline like Kafka queue size, auto-commit time interval, HTTP concurrency and so on. This resulted in a very lengthy configuration with many values which sources could become obscure after some time.
To address this, we provided well-considered default values for all parameters in Golissimo v2. This had the benefit of shortening the configuration file and also allowing us to make most pipelines benefit from gradual fine-tuning of those default values.
Modular data formats, transports and processing
Golissimo’s use cases are very diverse so to simplify maintenance and remain able to add new features easily, we organized most of the code as modules that support:
- Message formats: we use very diverse formats across our infrastructure either for optimization or historical reasons. They are constantly evolving as we add new features to our products.
- Message transports: our pipelines can be configured with either Kafka topics or REST APIs as data sinks.
- Processing algorithms: we routinely have to filter messages, doing database look-ups to route messages, multiply them for benchmarking, etc.
This design makes us able to support new use cases or data format changes just by tweaking the configuration, without having to write any code.
Monitoring and alerting
Like most of our services, Golissimo publishes Prometheus metrics that are collected and aggregated in Grafana dashboards. To be able to detect issues and find their root causes quickly, we wanted to show just the right level of detail so we built one global high-level dashboard as well as one in-depth dashboard for each region.
Some Golissimo pipelines are more critical than others: if they involve real-time production data for our customers, we want to be alerted immediately when an issue arises, even if that means waking up some of our on-call engineers. Other pipelines, such as those transferring data from production to staging at night, are less critical and should be categorized accordingly.
As an example of smart default configuration values, we made the criticality of pipelines that push data to production sinks high by default, and low otherwise.
In addition to standard Prometheus metrics, we also built a web endpoint to help us optimize Golissimo through CPU profiling with Go’s pprof tool. As you will learn in the next section, it proved so useful in a development context that we kept it available in production.
Optimizing Golissimo
As Kent Beck once put it:
Make it work. Make it right. Make it fast (In that order!).
In that spirit, our initial focus was on an early, naive implementation that helped us verify the correctness of our new design and establish the overall code organization.
The next phase was to iteratively work on a series of optimizations, from low-hanging fruit to more challenging ones. We will detail some of them below.
Optimization #1: Limit memory consumption
We use librdkafka to communicate with Kafka. It is a very mature and efficient library but we quickly discovered that it had very high default values for both consumer and producer queue sizes.
This became an issue for us because our traffic is very elastic and some Kafka sinks can be hit pretty hard during spikes, up to the point of becoming slow or unresponsive for a while. With a high queue size, this meant buffering a lot of messages in the pipeline while we waited for the sink to ingest them all, sometimes producing Out Of Memory errors and crashing Golissimo.
To address this, we set a lower memory limits for all pipelines so that they have a maximum number of messages in transit between a source and its sink, after which we stop reading new messages completely. This effectively implemented backpressure, which is a very desirable feature of production-ready data pipelines.
One slight downside of librdkafka is that it is written in C, hence its memory allocations are not visible to the Golang runtime. This made profiling memory usage a bit more painful but luckily this was a rather simple investigation.
Optimization #2: Survive TCP connection problems
During one of its first runs, we configured Golissimo to translate incoming Kafka messages into REST calls but introduced an error in the configuration (the REST endpoint host didn’t actually exist).
This led to 47% CPU time spent in the net.goLookupIPCNameOrder function:
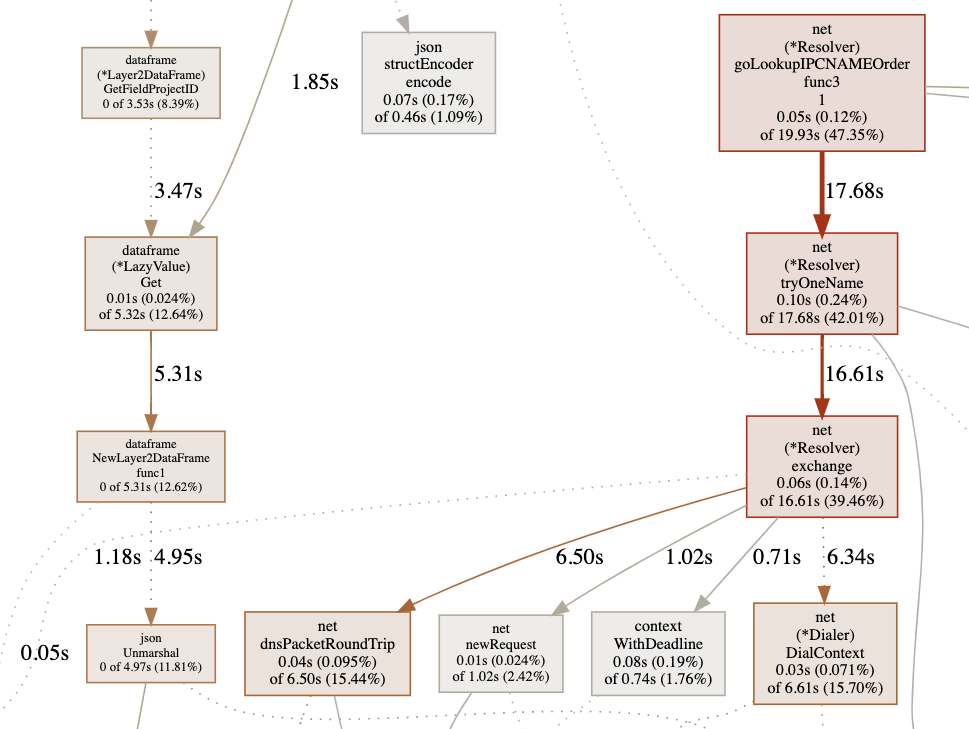
What was happening became obvious with this trace: a name resolution was being attempted for each message. Errors in configuration or network issues can occur, and in such cases, we don’t want the CPU to be fully consumed, as it would affect other streams running on the same instance. Ideally we want each pipeline execution to be as independent and isolated as possible even if they are running on the same Golissimo instance.
To mitigate this, we added an exponential backoff when network errors occur. Requests are still retried indefinitely but the exponential backoff means they won’t consume all the CPU meanwhile. This has the added benefit of quickly stopping the consumption of Kafka messages while waiting for the network error to be recovered, strengthening backpressure.
Optimization #3: Use a third-party JSON library
Although we are progressively moving our different message formats to more efficient representations like Protobuf, we still have many messages
encoded in JSON. The associated json.Marshal and json.Unmarshal function calls to the Go standard library were appearing quite a lot in the CPU profiles during our benchmarks.
We decided to address this by trying go-json.
Not only is it faster than the standard encoding/json package, but its key advantage is using the exact same API, making it a potential drop-in replacement with free performance benefits.
This has proved to be true for us: our profiling graph shows that go-json consumes 3 times less CPU than encoding/json. Easy!
There are more optimized JSON libraries for Go but they use a different API so we would need to re-specify our data structures and make developers learn the new API. This might be a good trade-off in the future but for now we are happy with the gains of go-json.
Optimization #4: Don’t reserialize unmodified messages
While profiling a pipeline doing only simple message forwarding with filtering, we saw that 23% of the CPU time was being spent decoding and re-encoding messages. Clearly there was something to do here.
At this stage, Golissimo was naively performing these steps for all pipelines:
- Read a message from the source.
- Unserialize its data into a structure, usually JSON or Protobuf.
- Run the processing modules, which can be filters based on some of the structured data fields or updates on some other fields.
- Reserialize the data.
- Send the message to the sink.
- Commit the message at the source once confirmed by the sink.
Most of the pipelines we are configuring involve some filtering to know if the messages should be transferred to their sink or not. This means that the parsing stage (step 2) is almost always needed. But in many cases we forward the message to the sink as it arrived, without any change. In those cases, reserializing (step 5) unnecessarily consumes CPU to reproduce the same payload we received from the source.
To optimize this frequent case, we decided to implement a lazy copy mechanism which would avoid reserializing the structured data to raw bytes when a message hasn’t been updated.
The main problem is that we want this mechanism to be transparent for the developers who will create new payload formats. We don’t want to burden them with those technicalities. Moreover, this mechanism should be automatic and generic because it mainly depends on the pipeline configuration.
The solution we came up with was to introduce an internal API to access the message and possibly change it. This API guarantees that we get the desired behavior and that processing modules in the code cannot change the data without Golissimo’s engine being aware of it. It adds a layer over the raw messages and looks roughly like this:
type MessageFrame interface { ReadField(fieldName string) interface{} PrepareModifications() MessageModifications}
type MessageModifications interface { SetField(fieldName string, value interface{}) Build() MessageFrame}With this API, if a processing module wants to transform a message, it will need to call PrepareModifications() to access a modifiable version of the data.
Golissimo will then set a flag to signal that a lazy copy cannot be done when sending to the sink, instead requiring a full reserialization to be done.
Thanks to this strongly typed API, we managed to minimize the mental burden for developers while enabling an automatic optimization in a common case. This led to a reduction of about 23% CPU time compared to the naive implementation!
Optimization #5: Batch commits
To ensure the safety of Golissimo even in hard shutdowns, we needed to disable auto-commit so that each message in the source Kafka would be committed only once confirmed at the pipeline’s end.
However, committing each message individually would be both very slow and highly unpractical. Indeed, commits on Kafka must remain monotonic whereas our pipelines usually involve synchronous filtering steps that can drop messages early and make their confirmation arrive much faster than unfiltered messages having to do a full round-trip to the data sink. To commit them in the right order at the source, we would need to keep a lot of them in memory while their priors are still getting processed.
To fix this, we introduced a batch commit algorithm that helped us balance commit frequency and memory usage.
First, we created two commit buckets for each pipeline: an open one where new messages arrive and a closed one that is waiting for all its messages to be confirmed.
Instead of storing every message offset in these buckets, we decided to make them a lightweight data structure that only stores 3 fields:
- the
maximum offsetseen for each partition from which it reads messages - the
total countof messages that it contains - the
acknowledged countof its messages that have been fully processed
For each pipeline, a unique goroutine acts both as a Kafka reader and a bucket manager:
- It registers newly consumed messages to the currently open bucket using their
Opaquefield provided by librdkafka for this kind of purpose. - It increments the
total countandmaximum offsetof messages in that bucket. - When receiving a message confirmation from the pipeline, it increments the
acknowledged countof the right bucket. - Every 5 seconds (which is configurable), it checks if the
acknowledged countand thetotal countof the closed bucket are equal, which means that all messages with offsets inferior to themaximum offsethave been processed. In this case, it commits thatmaximum offsetto the Kafka source, closes the current bucket and opens a brand new one.

Extra care was taken when implementing this algorithm to ensure thread safety and minimize the use of locks or atomics. That code never appeared in our CPU profiles, so we are good for now!
Optimization #6: Mutualize data source consumers
After Golissimo v2 entered production, we didn’t stop making improvements and it became more powerful over time, leading to even more internal usage which justified continued investment. This created a positive feedback loop, leading us to discover new scalability challenges.
For instance, as the number of pipelines grew even beyond what we had anticipated, we started to notice a real impact on the performance of some of our Kafka clusters because we were creating so many new consumer groups for all the Golissimo pipelines. This was particularly painful during traffic spikes like Black Friday that can put a lot of stress on our infrastructure.
When we analysed the overall network bandwidth usage, we saw that many Golissimo pipelines were reading independently from the same data sources, leading to a waste of resources. It would be optimal to find a way for them to share the same Kafka consumer group.
Unfortunately, mutualizating Kafka consumers groups means sharing the same Kafka commit offset at the source of all those pipelines. And if one of the pipeline sinks ever stops receiving and confirming messages, we would need to stop consumption for all the others to guarantee at least once semantics. We can only commit once all the downstream pipelines have confirmed a message.
This is a case where we have a clear trade-off to make between performance and resiliency. If we mutualize everything we will end up mixing the SLOs of production and staging that are very different, but if we don’t mutualize anything we are leaving performance (and money!) on the table.
In the end, we decided to only mutualize consumers for pipelines that share the same data source and which sinks are in the same environment (production, staging, dev). To cover advanced use cases, we let users override this behavior through configuration.
Once this was done for all eligible pipelines, we measured the gain in network consumption and found it to be between 25% and 50% depending on the level of mutualization achieved. We now read on average 2.4 times fewer messages than before across all Golissimo instances!
Optimization #7: Autoscale with cooperative sticky rebalance
Removing or adding a consumer in a consumer group interrupts the message consumption for all consumers because Kafka enters a long rebalance procedure which begins by unassigning all partitions from all consumers and can take as much as one or two minutes with default settings.
This would pose a challenge for autoscaling Golissimo, potentially causing Kubernetes pods to scale up and down rapidly. In the worst case this might stop message consumption indefinitely and we can trust Murphy’s law to make it happen eventually…
Ideally we shouldn’t need to stop all consumption when adding or removing a consumer in a group. The Kafka team is very aware of this problem and since the version 2.4 of Kafka, a new rebalancing mode named cooperative sticky has been added to fix this issue.
This is where we catch up with our current work: we recently enabled cooperative sticky mode in Golissimo and found that it was working well in staging, so we plan to push it to production soon!
Conclusion
The conception of the Golissimo v2 was made by having a broader vision in mind than just a revamp of the code. This allowed us to tackle critical design issues and make it a great fit for our current (and hopefully future) use cases.
Judging by its quick adoption internally, it has been a great success, with the added benefit of getting rid of a lot of custom-built data pipelines, hence simplifying our infrastructure.
We are also enjoying the benefits of our incremental approach to optimization. At this point, when inspecting CPU profiles, we see the CPU time spread almost equally across a lot of Go functions, which means that we are probably out of low-hanging fruit.
However, we still have quite a few ideas in mind to improve Golissimo, for instance looking at ring buffers or slab allocation to optimize memory footprint. This might lead us to switch to another Kafka client library, preferably one that would be Go-native.
Our goal remains to find efficient ways to provide a better service to our customers and their users. Golissimo v2 was a great step towards that never-ending goal!
Thanks to Romain Kirsbaum, Jonathan Meyer and Sylvain Zimmer for reviewing drafts of this article.