Making ClickHouse on Azure Blob Storage fast with s3proxy
At Contentsquare, we are operating our data pipeline on two prominent cloud providers: AWS and Azure. While this approach offers remarkable flexibility to our customers in choosing their preferred data storage location, it’s a significant challenge for our R&D team since we have to ensure our services are cloud agnostic and working properly across both platforms, with consistent performance and reliability.
One of the sinks of our data pipeline is a data lake exposed to internal teams that enables efficient large-scale data analysis and reporting. Today, this data lake is built on top of ClickHouse with a traditional architecture in which data is stored on local disks. We are currently exploring a new cost-efficient solution with a ClickHouse cluster configured with remote object storage like S3 (AWS) or Blob Storage (Azure). This article shares the struggles we faced with the native Azure Blob Storage implementation on ClickHouse, in comparison to the performance achieved with the S3 implementation and how we managed to find a reliable alternative to it.
ClickHouse with external disks
For a few releases, ClickHouse has been offering us a new way to store the data by using external disks like Amazon S3 or Azure Blob Storage instead of a local disk. For the users, it comes with multiple advantages:
- Scalability: when reaching the maximum capacity of your local storage, you have to increase the disk size or add more disks while it’s handled implicitly with the Blob Storage system since the storage is considered as unlimited.
- Availability: in case of crash, you may face a data loss with local disk that often requires a replication of your data. When relying on a system like S3 or Azure, the data availability reaches up to 99.9% which gives a strong guarantee on the data safety.
- Cost: the billing of a local disk is fixed at a price even if you have not used 100 % of its capacity while on S3 or Azure Blob Storage, you’re paying for what you store and helps to reduce the cost on the storage side.
Configuration
Using an external disk with ClickHouse requires updating its default configuration by either changing the file
/etc/clickhouse-server/config.xml or adding a new file /etc/clickhouse-server/config.d/storage.xml. For instance,
the following configuration shows how to add a S3 Disk (AWS) or a Blob Storage Disk (Azure).
<?xml version="1.0"?><clickhouse> <storage_configuration> <disks> <S3> <type>S3</type> <endpoint>http://path/to/endpoint</endpoint> <access_key_id>your_access_key_id</access_key_id> <secret_access_key>your_secret_access_key</secret_access_key> <region>eu-west-1</region> </S3> <blob_storage_disk> <type>azure_blob_storage</type> <storage_account_url>http://xxx.blob.core.windows.net</storage_account_url> <container_name>container</container_name> <account_name>account</account_name> <account_key>pass123</account_key> </blob_storage_disk> </disks> </storage_configuration></clickhouse>We can check that the disks are available in ClickHouse by running the following query:
$ SELECT name, type from system.disksQuery id: 40b77434-ecbe-442a-811a-e9ba5bec37a1┌─name─────────────────┬─type────────────────┐│ S3 │ s3 ││ blob_storage_disk │ azure_blob_storage │└──────────────────────┴─────────────────────┘Finally, let’s configure our table with an external disk by explicitly specifying the disk name when creating it:
CREATE TABLE mytable (...) Engine = …. SETTINGS disk = ‘S3’Benchmark
One of our Data Engineers contributed initial support for Azure Blob Storage disks and this implementation is working but not yet as fast as S3 disks. Indeed, the ClickHouse team has made drastic performance improvements to S3 support since but they haven’t ported them to Azure Blob Storage yet.
How big is this difference? We compared some KPIs including the query duration, the CPU and the Network Usage on both cloud providers using a benchmark of 15k queries from our production workload:
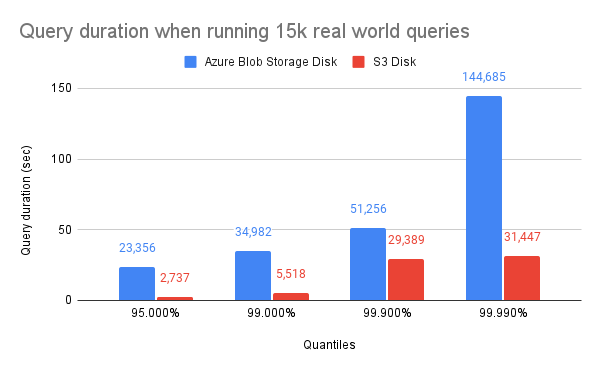
As you can see, all queries are running significantly faster on S3: the whole benchmark takes 10 hours to run on Azure Blob Storage but only 2 hours on S3! The S3 Disk implementation of ClickHouse is able to use the available CPU resources and network bandwidth more efficiently:
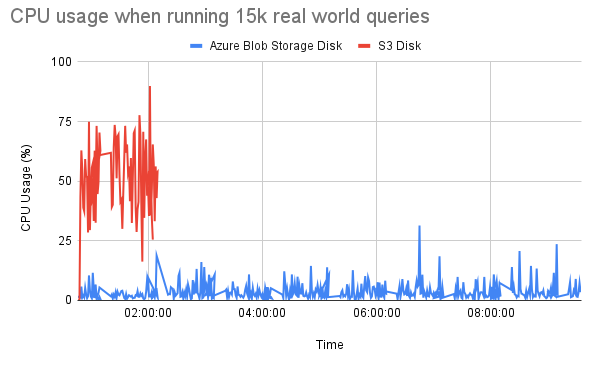
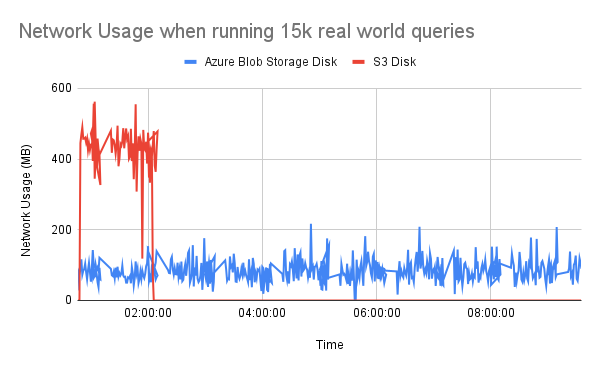
Due to our intensive production workload, it’s unfortunately not acceptable for us to use the ClickHouse Azure Blob Storage in its current state. While waiting for the ClickHouse team to port some of their optimizations, we started wondering if there wasn’t a short-term workaround…
Introducing s3proxy
s3proxy is an open source project that implements the S3 API as an input interface and translates it to multiple backends that include AWS, GCP and Azure. The project is internally based on Jetty for the HTTP server part and Apache jclouds for the multi-cloud blobstore abstraction.
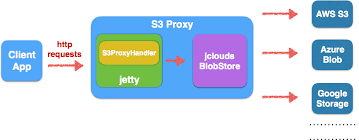
We decided to experiment with a deployment of s3proxy between a ClickHouse server and Azure Blob Storage. As with most of our infrastructure, we used Kubernetes to easily manage its scalability. s3proxy is CPU & IO-intensive so it is a good fit for having multiple replicas serving queries in parallel.
It was not necessary to deploy a load balancer on top of the replicas since the Kubernetes Ingress can dispatch the requests from ClickHouse to the replicas itself.
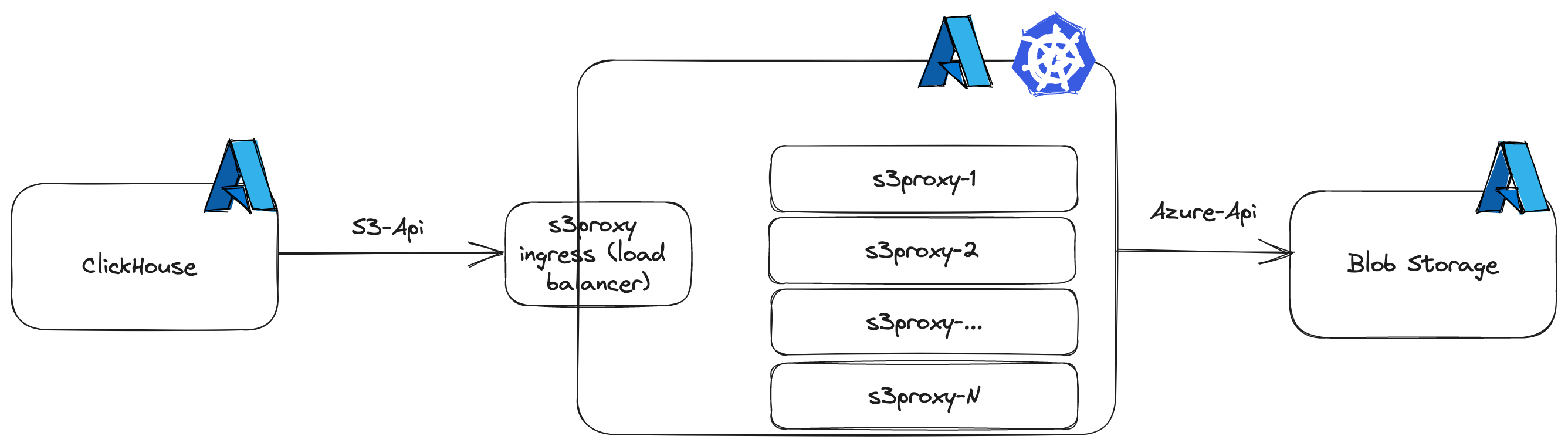
With this configuration, ClickHouse is actually using its S3 disk support with all its optimizations, but in reality it is targeting Azure Blob Storage through s3proxy.
So, how fast can it get?
Benchmarks
Setup
After some initial promising results, we decided to run a full round of benchmarks with different setups to have a definitive answer.
We deployed ClickHouse (CH) in a single VM with the same number of CPUs and almost the same Network Bandwidth. For s3proxy, a small benchmark helped us identify that 4 replicas were giving the best performance without any tweaking settings on the proxy level. On AWS, we also decided to benchmark s3proxy between a ClickHouse instance and AWS S3 to measure its overhead:
| Setup | Instances | vCPU | Network Bandwidth | Memory |
|---|---|---|---|---|
| S3 disk (AWS) | CH: 1x r6i.8xlarge VM | CH: 32 | CH: 1,5 GB/s | CH: 256 GB |
| S3 disk + s3proxy (AWS) | CH: 1x r6i.8xlarge VM s3proxy: 4x k8s EKS | CH: 32 s3proxy: 3 | CH: 1,5 GB/s s3proxy: 1 GB/s | CH: 256 GB s3proxy: 3 GB |
| S3 disk + s3proxy (Azure) | CH: 1x E32as_v4 VM s3proxy: 4x k8s AKS | CH: 32 s3proxy: 3 | CH: 1,5 GB/s s3proxy: 1 GB/s | CH: 256 GB s3proxy: 3 GB |
Using the system.query_log table, we built a dataset of 28K queries to replay using the native clickhouse-benchmark
tool. All the queries read from a single table (~200 columns) that has a compressed size of approximately 7.5 TB.
To have the most consistent benchmark possible, we replayed the exact same dataset on each setup.
Benchmark duration
The whole benchmark ran for 40 minutes with the S3 disk on AWS, 42 minutes with the S3 disk and s3proxy on AWS and 45 minutes with the S3 disk on Azure. Compared to the native Azure Blob Storage disk, these findings provide highly positive feedback, confirming a promising outcome from our initial benchmarks.
Query Duration
The following chart plots the query durations from clickhouse-benchmark for the most
interesting quantiles (95 to 99.999 %) with each setup:
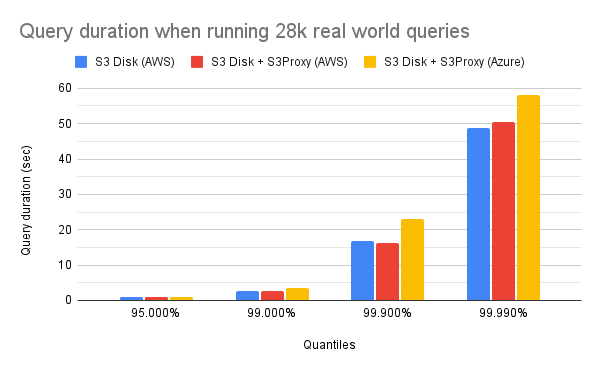
These results already give us some insights:
- s3proxy is introducing minimal overhead as both setups on AWS, with and without it, are showing similar performance.
- The setup on Azure is still slower than the setup on AWS without s3proxy: on average, ClickHouse experiences a 27% decrease in speed on Azure compared to AWS.
Overall, the difference in performance between AWS and Azure has now become acceptable for us with s3proxy, in contrast with the native Azure Blob Storage implementation.
CPU Usage
Based on our observations from the first benchmark, it is obvious that ClickHouse is using the CPU on Azure inefficiently, which that results in poor overall performance. With the s3proxy setup, this concern has been mitigated. The CPU usage on Azure now aligns closely with the AWS one which highlight the significant performance improvement:
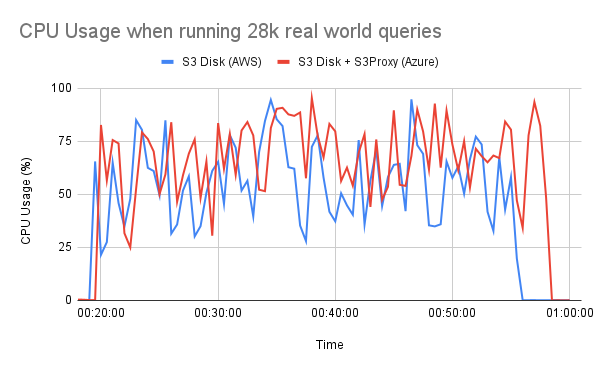
Network Usage
The performance of reading remote disks like S3 is scaling linearly with the number of cores available until reaching the physical Network limits of the machine. As discussed earlier, the improved CPU utilization of ClickHouse must contribute to higher network throughput:
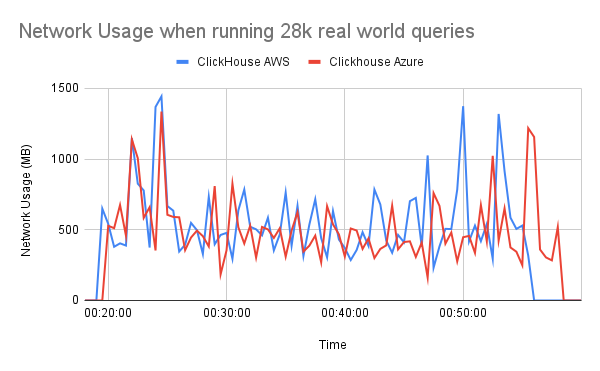
This hypothesis is confirmed by analyzing the Network metrics of our ClickHouse clusters in AWS and Azure, where the Network Usage on Azure and AWS are very close, in addition to the observed CPU similarity. Consequently, based on the observed CPU and Network Usage, we now have a better setup for using ClickHouse with an S3 disk on Azure.
Feature parity
The daily usage of our ClickHouse clusters is not limited to reading and writing data. To ensure optimal read performance, we are running a daily optimization of our tables and we are occasionally altering them to delete data.
Whatever the cloud provider, it is important to have the same level of feature parity across our ClickHouse clusters. Hence, a relevant question arose concerning s3proxy, would there be a compromise between feature parity and performance? We can share that, at least from a functional perspective, all these features are working with s3proxy on Azure:
| Feature | S3 Disk (AWS) | S3 Disk + s3proxy (Azure) |
|---|---|---|
| Write | ✅ | ✅ |
| Read | ✅ | ✅ |
| Optimize | ✅ | ✅ |
| DROP | ✅ | ✅ |
| Mutations | ✅ | ✅ |
Conclusion
Transitioning ClickHouse from local disks to remote disks represents a significant challenge, but having to maintain consistent performance levels across various cloud provider makes it even more complex.
We hope the insights shared in this article will help the ClickHouse community members who find themselves in a similar situation. Finally, now that we proved that it can be done with a proxy, we hope that the ClickHouse team will be able to align the performance of Azure Blob Storage disks with S3 disks natively!
Thanks to Elsa Donovan, Emre Karagozoglu, Olivier Devoisin, Sylvain Zimmer and Youenn Lebras for reviewing drafts of this.