NeurIPS 2021: Does the data really speak for itself?
Data is at the heart of what we do at Contentsquare, and apparently we are not alone in this. Data is also at the heart of AI nowadays, so much that it deserved its own track at NeurIPS. More than 170 papers (out of 500 submitted) specifically on data resulted in the Datasets and Benchmarks track, 3 sub-tracks, 4 poster sessions and a symposium.
Main question is: do we even know what a good benchmark is? Do we know how to measure the quality of our data?
Is data really everywhere?
Once upon a time, AI was mostly about models (that used little or no training data), and their optimization algorithms. The approaches were evaluated by mathematical theory, or using artificial data designed for the problem the model is trying to solve.
Nowadays, it is still about models, but both the training and evaluation shifted on the data. Take a random AI paper - there is a good chance you will come across some commonly used dataset, either for training or evaluation.
This meta-review of evaluation failures gives more detailed analysis on those chances:
Concretely, we randomly sampled 140 papers from the past five years (2016–2021) of NeurIPS, ICML, EMNLP, and CVPR, and filtered out papers which were not applicable to the benchmarking paradigm (37 papers). … On average, papers evaluated on an average of 4.1 datasets and 2.2 metrics. Overall, most of the papers in our sample (>65%) evaluate on 3 datasets or fewer, and a similar fraction (>65%) evaluate on 2 metrics or fewer.
This paper about metrics analysis also provides some interesting insights by analyzing 3867 papers from “papers with code”. Below we can see the number of benchmarks per high level process:
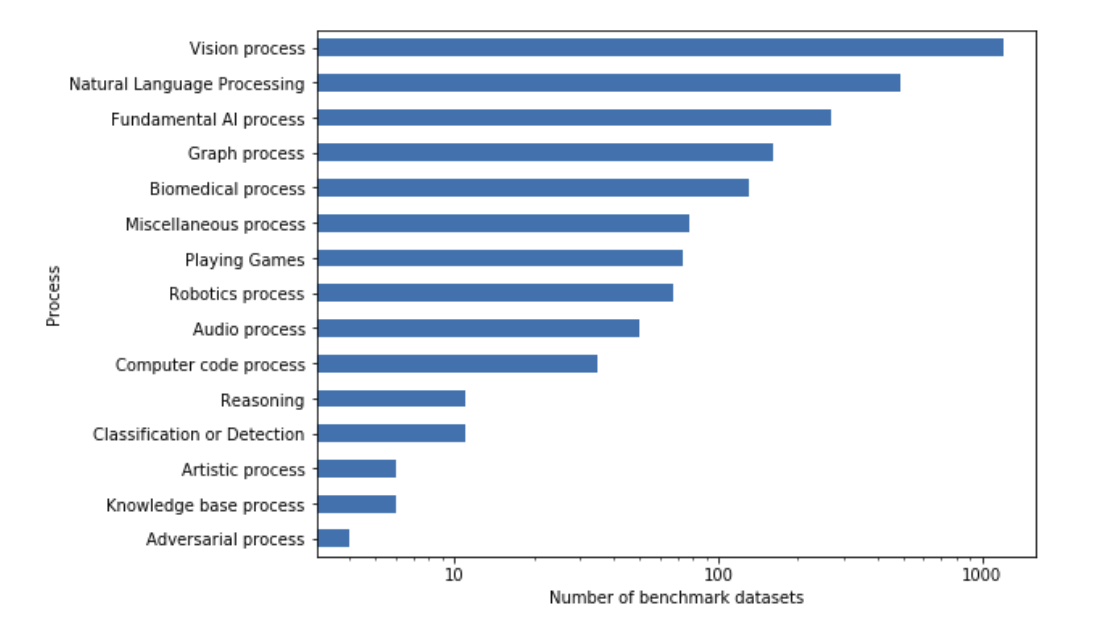
Regarding the results reporting, it seems that accuracy is the top metric. 77% of papers use only one metric, 14.4% two metrics, 6% three metrics. We can already spot a red flag here:
When a measure becomes a target, it ceases to be a good measure.
(This is also known as Goodhart’s Law.)
What is the problem?
Seems like we established a solid procedure for AI research in different topics - come up with a model, train it on the train data, test it on the test data, show that you got a better number than the previous papers and you got yourself a paper.
What is the bad news? Here is a story from one of the NeurIPS papers named AI and the Everything in the Whole Wide World Benchmark:
In the 1974 Sesame Street children’s storybook Grover and the Everything in the Whole Wide World Museum [Stiles and Wilcox, 1974], the Muppet monster Grover visits a museum claiming to showcase “everything in the whole wide world”. Example objects representing certain categories fill each room. Several categories are arbitrary and subjective, including showrooms for “Things You Find On a Wall” and “The Things that Can Tickle You Room”. Some are oddly specific, such as “The Carrot Room”, while others unhelpfully vague like “The Tall Hall”. When he thinks that he has seen all that is there, Grover comes to a door that is labeled “Everything Else”. He opens the door, only to find himself in the outside world.

This story nicely illustrates the question: is data/task-based progress on a continuum with general AI? (The point being raised in this paper that discusses the difficulties of general AI.) This question about general AI is a tough one, and maybe for now we can put it aside because there are more tangible problems in our current datasets and benchmarks we can tackle, and which might be solvable in the shorter term.
Previously mentioned paper about evaluation failures presents the problem of benchmark-based evaluations by dividing the issues in internal and external. Below we can see the framework for benchmark based evaluations of machine learning algorithms and associated validity concerns:
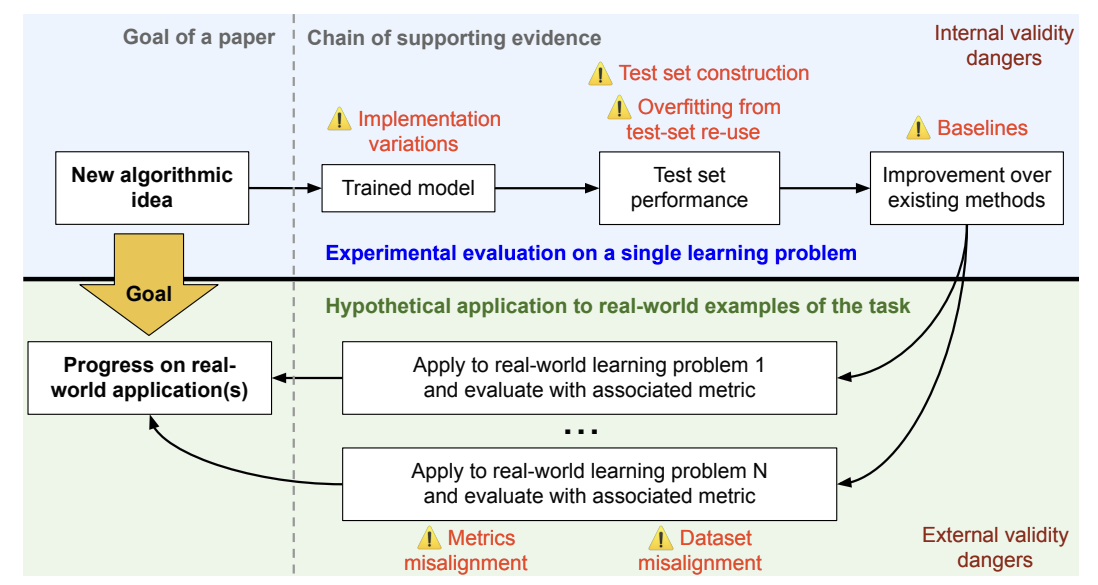
Potential internal validity issues in benchmarking steps are:
-
Implementation variations in trained models, when variations in algorithm implementation cause large variations in algorithm performance.
-
Test set construction errors, which includes erroneous labels, label leakage (when data features contain information about the target variable), inappropriate test set size, and contamination such as containing duplicates.
-
Overfitting from test set reuse. Repeatedly reusing popular test sets for model selection breaks the assumption that the model will generalize to the data from the same distribution. The connection between the test set and its corresponding data distribution is only guaranteed if the test set is not reused frequently.
-
Inadequate baselines, like untuned algorithms that perform better once fine-tuned. There is also the problem of human baselines. Those are often poorly computed, and inconsistencies in human annotations are not handled well - annotations try to decrease the disagreement, rather than incorporate it. Furthermore, sometimes annotations are not replicable with time.
External validity issues refer to problem of correlation between specific tasks and general AI:
Developing tailored algorithms for specific learning problems is usually not the end goal of machine learning research; rather, the hope is that the ideas and contributions will apply to broader scenarios. How much one expects progress to transfer is a subjective judgment based on factors such as the learning problems involved, the domain knowledge required, and the details of the algorithm itself. We refer to this as external validity, as it involves relationships between two or more learning problems.
Progress on learning problem A may transfer to learning problem B universally, but progress may also plateau or there may be no correlation between performance on the two learning problems. There is an illustration of this statement below:
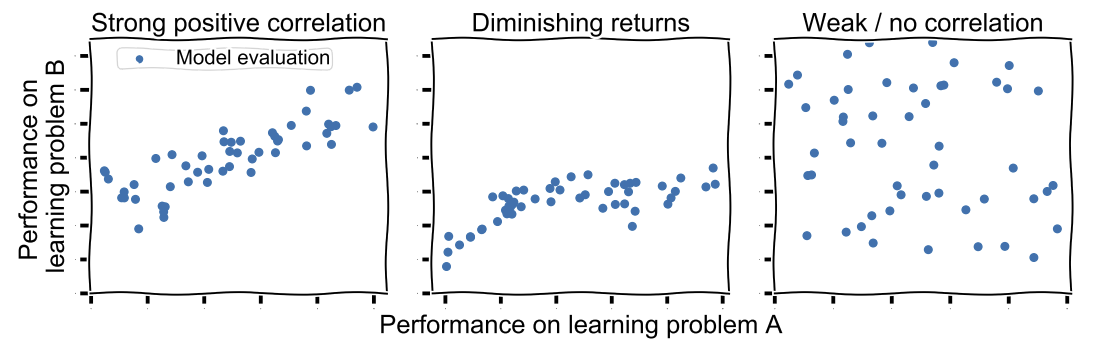
Some examples of external validity issues presented in the Whole Wide World paper are:
- Limited task design, meaning limited to the tasks we can do, rather than what we want to do. For example, it is easy to define a task of classifying cat images against dog images. But does high accuracy on classifying those images mean better visual understanding?
- De-contextualized data, when the data is taken out of its natural context without considering the effects of that. For example, in ImageNet objects tend to be centered within the images. But how would our models shift if we shift to the natural context?
- Inappropriate community use, especially by the academic community, where chasing numbers has become a standard practice for publishing papers. But real life works in a different way. For example, 80% accuracy on Iris classification might be sufficient for the botany world, but to accurately classify a poisonous mushroom, we should hope for something closer to 99%. Metrics might have the same range, but not the same meaning.
What can we do?
For example, we could analyze the effect of labeling errors on model benchmarking, as done in the paper Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks. The authors showed that in some cases only 6% of wrongly labeled data is enough to throw the benchmarking off. How did they do that? First they looked for errors in commonly used dataset, using their Confident Learning algorithm and MTurk validation. Their results on labeling errors in commonly used datasets are below:
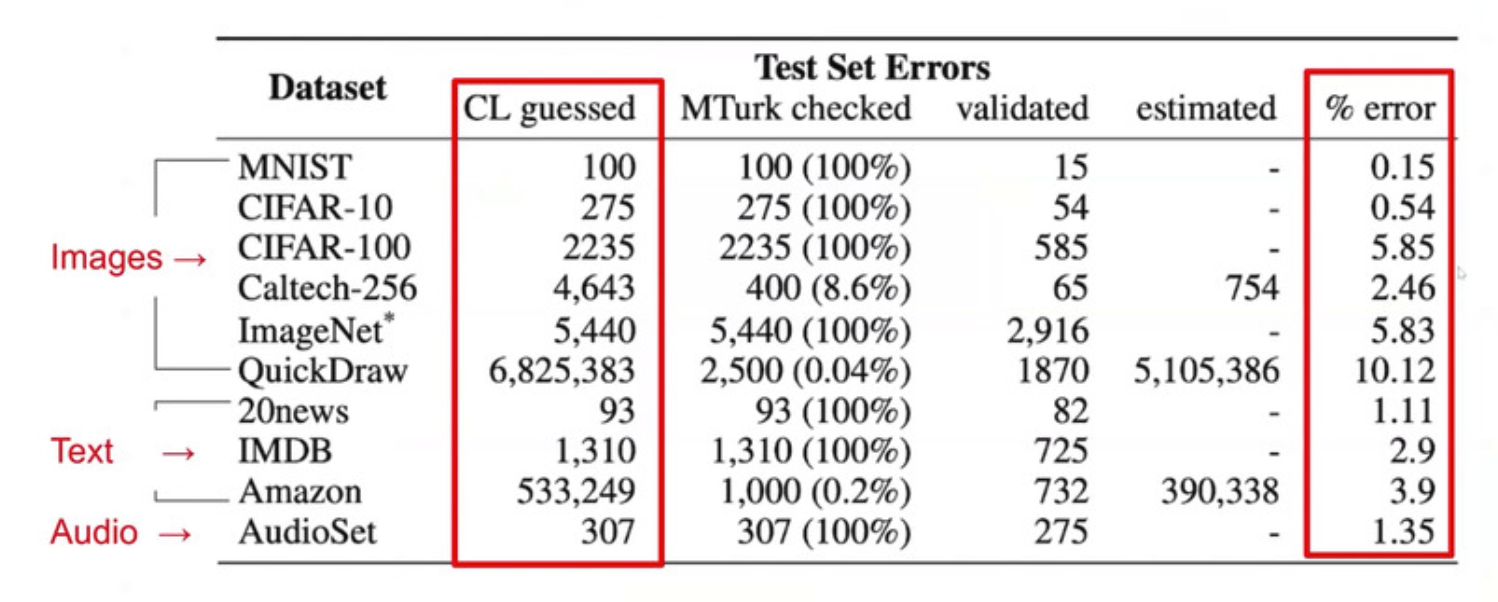
We can see that some are high, some are low, but none is perfect.
Then the authors corrected the errors and evaluated the models on the whole data that now did not contain any erroneous labels. Conclusions about model performance still held: more complex models still outperformed less complex ones.
Authors then did a final test - they evaluated models only on the data that had to be corrected. In this case, the conclusions about model performance did not hold anymore: less complex models were better than more complex ones.
The authors wondered how much noise (incorrect labels) has to be in the test data to make the model performance reversed? It turns out only about 6 percent.
This is not general to every data and model, but it is definitely not something one would expect for those well established dataset and models. Models are usually well established precisely because they outperformed less complex ones on some data.
Beside observing erroneous labels, we could also look at how easy it is to change label predictions of a (state-of-the-art) model by creating adversarial examples.
There is a paper in the NLP area that does exactly that and by doing so, it is addressing specifically the vulnerabilities of the famous GLUE dataset. They take examples from the GLUE data and perform different perturbations to create adversarial examples that can fool the state-of-the-art language models (such as BERT, RoBERTa and RoBERTa ensemble). They create AdvGLUE dataset that aims to fool the language models, and indeed, all the language models perform poorly on AdvGLUE.
Note that they applied 14 textual adversarial attacks - this list is not final.
What can we at Contentsquare do?
We have been warned and we are aware that we will have to follow certain procedures to ensure good quality of our data. Beside that, we have to admit that we did find a couple of benchmarks for our problems - yes, all benchmarks are wrong, but some are useful.
Some of our topics are a bit outside classical Computer Vision and NLP scope, for which there is a vastness of materials, including benchmarks. This means additional challenges for us, but it also means that we should be less prone to fall into the benchmarking traps.
As we have an alerting system which acts on time series data, we are particularly interested in topics related to time series analysis, in particular forecasting, anomaly/outlier detection and causality. Those are all ill posed problems and looking over time series papers we got another confirmation that current AI struggles with such problems. There was not much work on that, either theoretical or the benchmarking types. (We did find a dataset of acoustic recordings of mosquitoes tracked in free flight. A bit far from our use case.)
In the end, we found a couple of relevant works. First is Revisiting Time Series Outlier Detection: Definitions and Benchmarks. This paper points to the problem of outlier ambiguities and proposes a taxonomy, that is outlier categorization, to relabel real world data:
… real-world outliers are complex and may not be well-labeled. This is caused by the unclear definition of the existing taxonomy, and may lead to confusion of the ability of algorithms. To better study algorithms, one approach could be creating realistic synthetic dataset with synthetic outliers […] However, validating in real-world datasets could be preferred by researchers. To achieve this, one may leverage the proposed taxonomy on existing datasets to re-label the real-world data directly.
This work provides insightful analysis of different types of model in outlier detection - it seems that in general classical Machine Learning methods still outperform Deep Learning for outlier detection.
Second work is Monash Time Series Forecasting Archive. This work also provides analysis on the performance of different models on different types of time series data. In their work, for low frequency data classical Machine Learning algorithms are better, but for high frequency data Deep Learning methods are better.
There is an interesting library/benchmark about counterfactual explanations that seems to be applicable for a wide range of problems: CARLA: A Python Library to Benchmark Algorithmic Recourse and Counterfactual Explanation Algorithms. Counterfactual explanations give insights about interventions to the input of a complex model so that the output changes to the advantage of an end user. This can be a nice way of modeling different questions, for example: what kind of feature of my product do I have to change to increase revenue? Should I advertise it more, on which platform, decrease the price, increase the visibility, etc? Those are some interesting questions for our clients too.
Conclusion
In a nutshell: yes, data speaks and gives you numbers. What those numbers speak in terms of general AI advances remains for future research. In the meantime, we need to make better datasets and benchmarks.
Many thanks to Tim Carry, Amine Baatout and Clement Pinard for their detailed reviews and discussions on the presented ideas.