How we scale out our ClickHouse cluster
Everything should be made as simple as possible, but not simpler.
— Albert Einstein
Summary
Any service that sees significant growth will eventually need to scale. This means growing the infrastructure larger (in compute, storage and networking) so that the applications riding on that infrastructure can serve more people at a time. It’s critical that scaling is done in a way that ensures the integrity of the data. Before starting, you need to understand the limitations to determine which solution provides the greatest benefit for you. Scaling operations can easily become expensive and complex in terms of performance and usability.
Scale Up vs Scale Out
There are two ways to scale: scaling up and scaling out:
Scaling upis replacing what you have with something more powerful.
Scaling outis duplicating the infrastructure capacity and be able to work in parallel.
Our motivation
Here at Contentsquare, we decided to scale out our cluster. In ClickHouse, the scaling operation is made of two parts. You first need to reshard (adding new shards), then rebalance (distributing your existing data across all those shards).

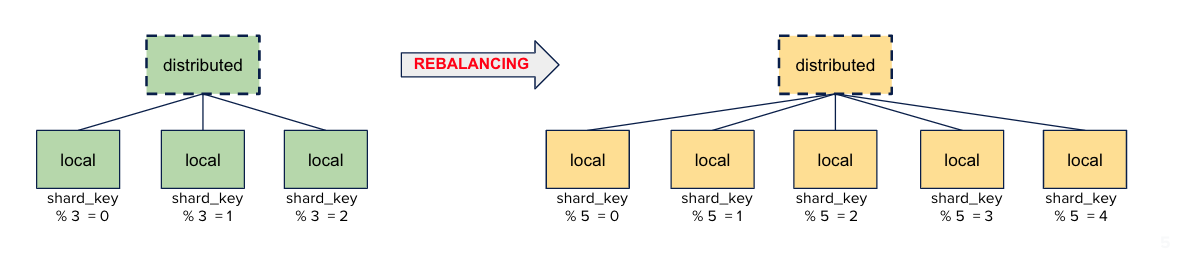
Rebalancing is needed to actually benefit from the scaling. If you do not rebalance your data, the new data will be distributed across your new topology but the existing and current data is still stored in your previous configuration. You will not benefit from the improvement of the scaling and will not preserve your capacity planning in terms of storage across all the shards.
The issue we faced was that ClickHouse doesn’t automatically rebalance data in the cluster when we add new shards.
That being said, ClickHouse comes with utilities to help you rebalance your data. Depending on your data topology and size, they all have their limitations in terms of performance and usability.
At Contentsquare, with the amount of data we add to ClickHouse every day, it was paramount that we kept 100% data integrity without impacting production speed. This article describes all the ways we explored before building our own. We hope it will help you better understand the tradeoffs and pick the one that provides the greatest benefit for your situation.
Solutions we explored
Solution #1: Kafka tables engines
The first idea we explored was using Kafka to externalize the process of rebalancing the data. Kafka is an important part of our data pipeline, and we already use it extensively.
ClickHouse can natively read messages from a Kafka topic. It uses the Kafka table engine coupled with a materialized view to fetch messages and push them to a ClickHouse target table. ClickHouse can also write to Kafka by inserting into a Kafka table. This allowed us to use Kafka as the infrastructure tool to rebalance data between two ClickHouse clusters.

-- Kafka tables engine to create in source and target clusterCREATE TABLE [src|dest]_table_queue ( name1 [type1], name2 [type2], . . .) ENGINE = KafkaSETTINGS kafka_broker_list = 'hostname:port', kafka_topic_list = 'topic1, topic2, ...' kafka_group_name = 'group_name', kafka_format = 'data_format' kafka_max_block_size = N ;
-- Create MV in target clusterCREATE MATERIALIZED VIEW dest_table_queue_mvTO dest_tableASSELECT * FROM dest_table_queue ;
-- Transfer data from source to target tableINSERT INTO src_table_queue SELECT * FROM src_table ;Each Kafka topic will contain data “ready” to be inserted into the rebalanced target cluster.

-- n is number of shard in target clusterfor each src_shard: for each src_table: for each date_partition: for each dest_shard (i: 0.. n-1): INSERT INTO src_table_queue(topic i) SELECT * FROM src_table WHERE date=date_partition and shard_key%n = i
-- this part is fully automaticfor each dest_shard: for each dest_table: is defined dest_table_queue attached to kakfa topic with materialized viewThis Kafka solution was promising. Because it is externalized to Kafka, we could tweak the ingestion traffic speed and resources automatically.
But, we decided not to use it. At least, not yet. We thought that the Kafka table engine in ClickHouse was not mature enough. Specifically, it is lacking a lot of logging features and we did not want to run it in production without a way to monitor it closely and debug if needed.
Solution #2: clickhouse-copier
Another solution that we explored was the naive way to copy data with clickhouse-copier.
clickhouse-copier is part of standard ClickHouse server distribution, it copies data from the tables in one cluster to tables in another (or the same) cluster. Zookeeper is used for syncing the copy and tracking the changes.
With clickhouse-copier, we explored 2 scenarios:
scenario #1: We thought about building an entire new cluster, and then migrate data with clickhouse-copier from source_cluster to target_cluster.
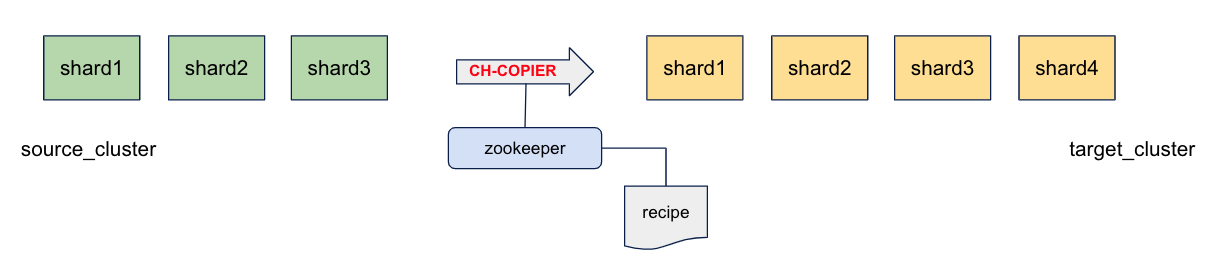
This solution is working well but, because it was operating on the production cluster directly (during the migration), it would have had an impact on our production performance. We considered it was too risky, so we looked for an alternative.
scenario #2: We then thought about using clickhouse-copier and creating a new database with more shards in the same cluster. We would have copied data from source_db to target_db. This is called resharding in place, because we stay in the same cluster.
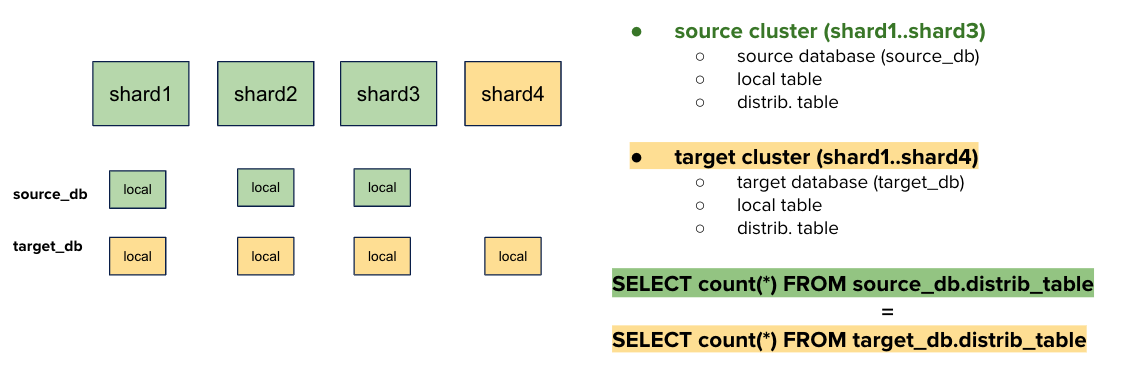
This Resharding in place solution is powerful and cost effective: a single cluster is used during the migration. However, we did not go with it because it would operate on our production server. It was not completely ignored however because we do use it in our built-in solution.
Our solution
Don’t make the process harder than it is.
— Jack Welch
All the solutions we tried had their drawbacks. We wanted something simple to reason about so it would be easy to automate and monitor. It also had to be scalable (should run quickly even with a large amount of data) and robust (so it could be stopped and restarted at any time). Finally, we also needed it to be cost-effective.
Before I describe our solution, it is important to introduce a vital tool that we use on a daily basis in Contentsquare: the mechanism of clickhouse backup/restore to easily save and restore our daily data with cloud storage support.
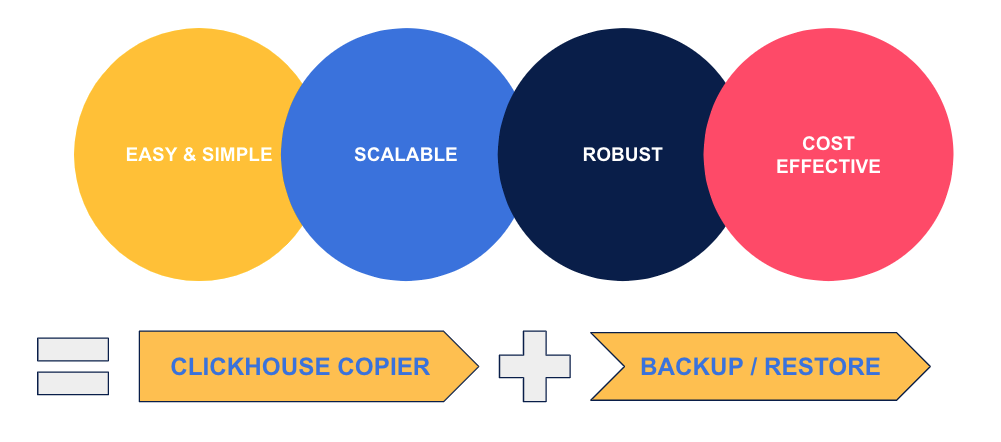
What we came up with uses clickhouse-copier, as well as our daily backups.
We call it our ClickHouse cooker, because it acts as some kind of pot where we put our ingredients (our backups), let them cook for some time, and then we extract new, rebalanced, backups from it.
We built this based on our findings exploring all the above ideas.
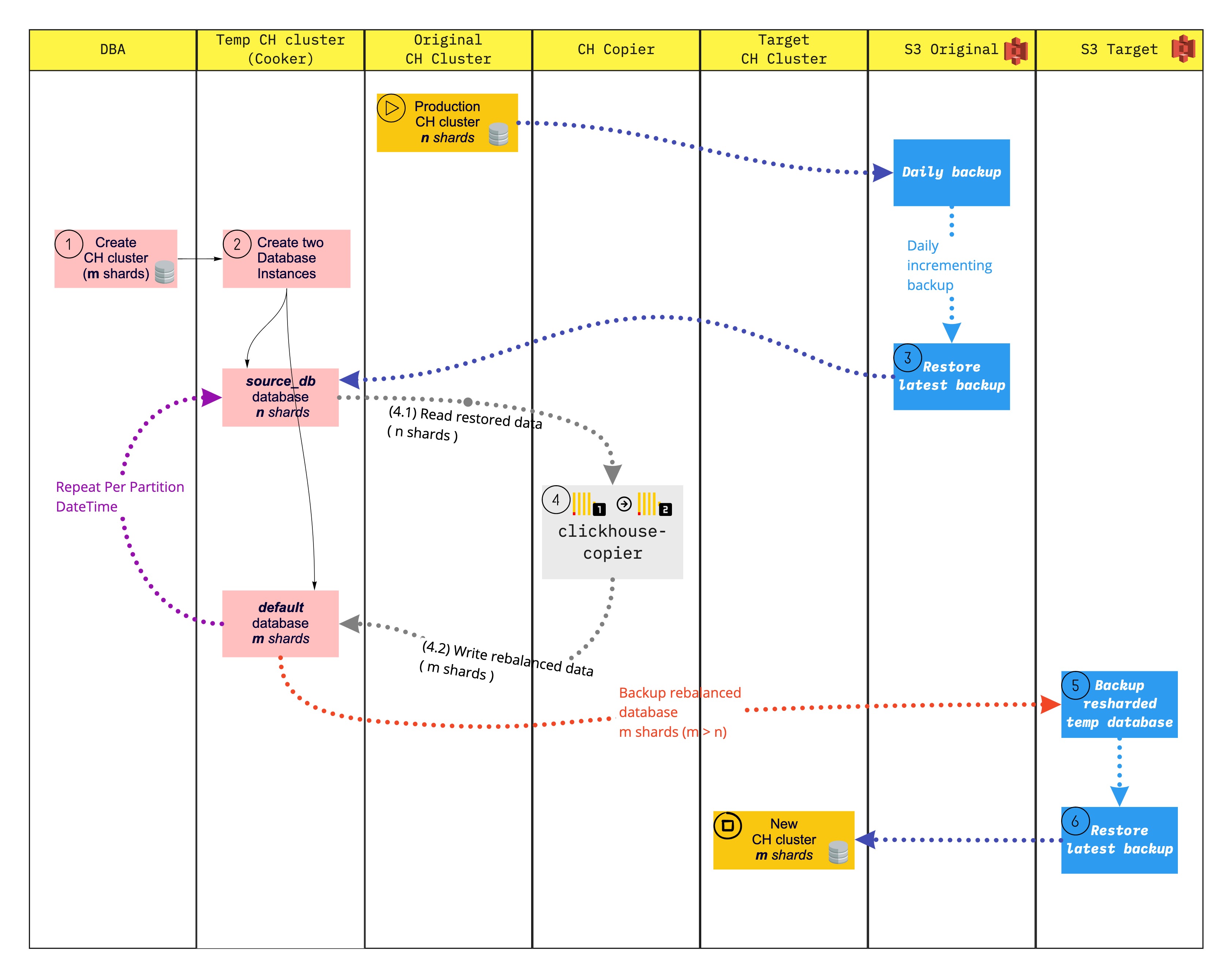
Let’s cook it! Below is the “recipe” to scale out our ClickHouse cluster from n to m shards
Ingredients / supplies
- The full backup copy of your original ClickHouse cluster in external storage (S3)
- The
ClickHouseresharding-cooker:- creates ClickHouse cluster (m shards) with 2 empty databases:
source_dbinstalled on n shards and default database on m shards (n<m) - using
clickhouse-backupto restore data intosource_db - using
clickhouse-copierto migrate data fromsource_dbto default (resharding in place) - using
clickhouse-backupto backup data from default
- creates ClickHouse cluster (m shards) with 2 empty databases:
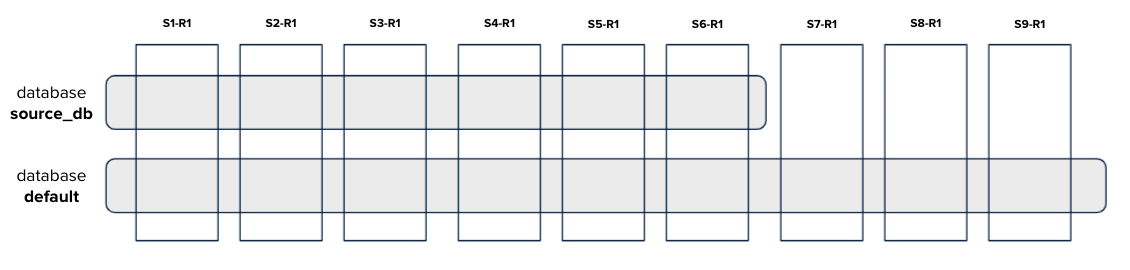
for each partition_key of table data :
# step 1 [clickhouse-client] remove/truncate data in source_db and default databases
# step 2 [clickhouse-backup] restore data from external_storage to source_db
# step 3 [clickhouse-copier] migrate data from source_db to default
# step 4 [clickhouse-client] check data between source_db and default (make sure all data from source_db have been fully migrated to default database)
# step 5 [clickhouse-backup] backup data from default to external_storage- When you’ve finished the previous loop operation for all the dates of your database (daily backup ready in the new topology), you need to:
- create a new ClickHouse cluster and
- restore in the loop the daily backup copies from external storage
This solution is fully scalable: you can deploy several clusters (with m instances each) and execute in a loop the daily operation described above.
This is it
Exploring so many different ideas was worth our while because we finally came up with one we are happy with. It is simple enough that it can be automated and scaled horizontally. Because of that, it also does not cost much and we can tweak its speed as needed.
Often, the simplest designs need the most thinking.
Thanks to the amazing DT team and in particular to Ryad for being a great support every day of this reflection and all the team for approving it: Vincent, Nir and Aryeh. And Thanks to Tim for helping me write this article.