SageDB, the Self-Assembling Database System
A few months ago, some members of Contentsquare’s Data Science team attended the NeurIPS conference. NeurIPS is one of the most famous AI conferences, with a broad range of subjects and delving deep into each.
We attended a workshop called “ML for Systems”. It presented ideas on how Machine Learning can help improve systems. We loved that angle because it was very different from the other talks. Traditionally, talks discuss systems for Machine Learning, how to make Neural Networks run faster, on smaller devices, or how to make training data easily with efficient databases. The workshop was different because it focused on making systems more efficient with Machine Learning, thus creating a virtuous cycle where Machine Learning and systems both help each other.
This article will mostly focus on the problem of how to improve Database technologies with Machine Learning, and especially on a talk given by Tim Kraska, an associate professor at MIT where he presented SageDB, a research project of MIT’s Data Systems and AI lab.
The limits of Moore’s law
The main premise of his talk was the problem of computing speed vs data volume.
Moore’s law is an empiric law which states that the number of transistors in a chip, and thus its computational power is following an exponential trend. This law has stood still until recently, but is getting more and more challenged because of the physical impossibility to construct transistors smaller than a few atoms.
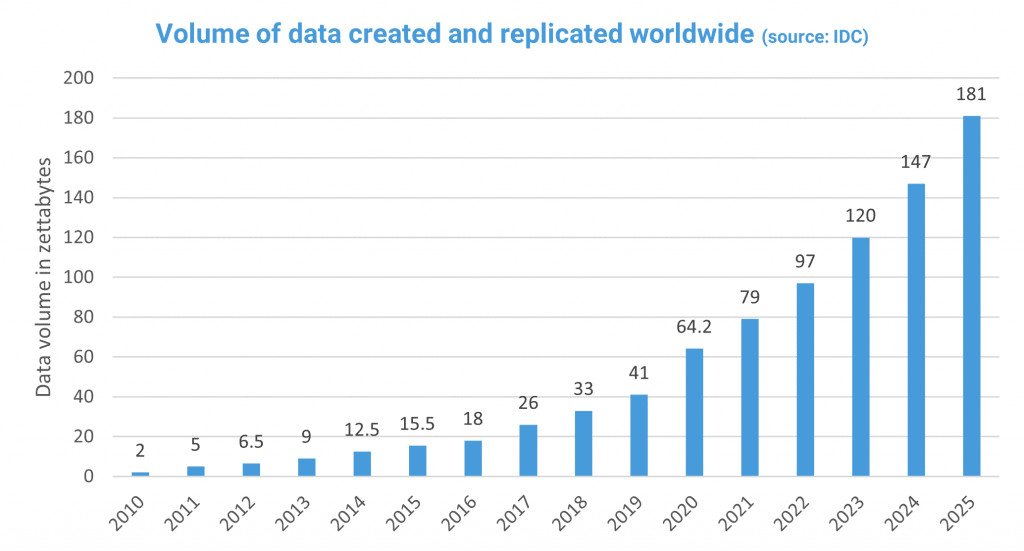
This is a problem because systems are getting more and more data hungry. The exponential trend of data volume created and replicated worldwide shows that soon Moore’s law is going to create a painful bottleneck.
How can we keep up the speed of data processing while Moore’s law is not working anymore?
One solution is specialization. Depending on the use case, you can provide a custom tailored solution that will leverage patterns in your task to optimize it.
A famous example is the case of easily parallelizable tasks such as Neural Networks. Getting simpler but more numerous processor cores will be very beneficial. This is exactly what a GPU is doing and why it is now used not only for graphic tasks but also computational.
Going even further, a Field-programmable gate array (or FPGA) will let you create the perfect processor for your task and its constraints with a method called hardware acceleration.
Having said that raises the question of specialized systems. The key idea is that many different database technologies exist, for example Redis for key-value fast reads or Prometheus for time series.
However, even if each database family is specialized for a specific subset of access patterns, the goal is still to be useful for a broad range of use cases within that subset.
If you had an unlimited amount of time and money, you could in theory be able to craft the perfect database for your use case. As you would know exactly the size and shape of your data as well as the queries made on it, you could optimize it to increase its speed and reduce its memory footprint.
But you don’t have unlimited time and money and adapting an existing database will most likely yield better results than building a new one from scratch.
This is the eternal question data engineers have to ask themselves as their company is growing:
Should I optimize my data model specifically for my database, or should I use a database already optimized for my data model?
Introducing SageDB, the Self-Assembling Database System
Tim presented a set of tools that were developed in the context of a broader project called SageDB.
The goal of this project is to develop a database technology that would learn on all leverageable patterns of the end user data and queries as if the pipeline was completely built from scratch by an expert.
This will allow the database to have both fast access, and low memory footprint, with a minimal development cost, which would be perfect for small businesses that don’t have the resources for developing or customizing a database the classical way.
The following section will cover three cherry picked tools that could be used on any database to improve the way we query data: learned indexes, grid database layout, and query optimizer.
Learned indexes
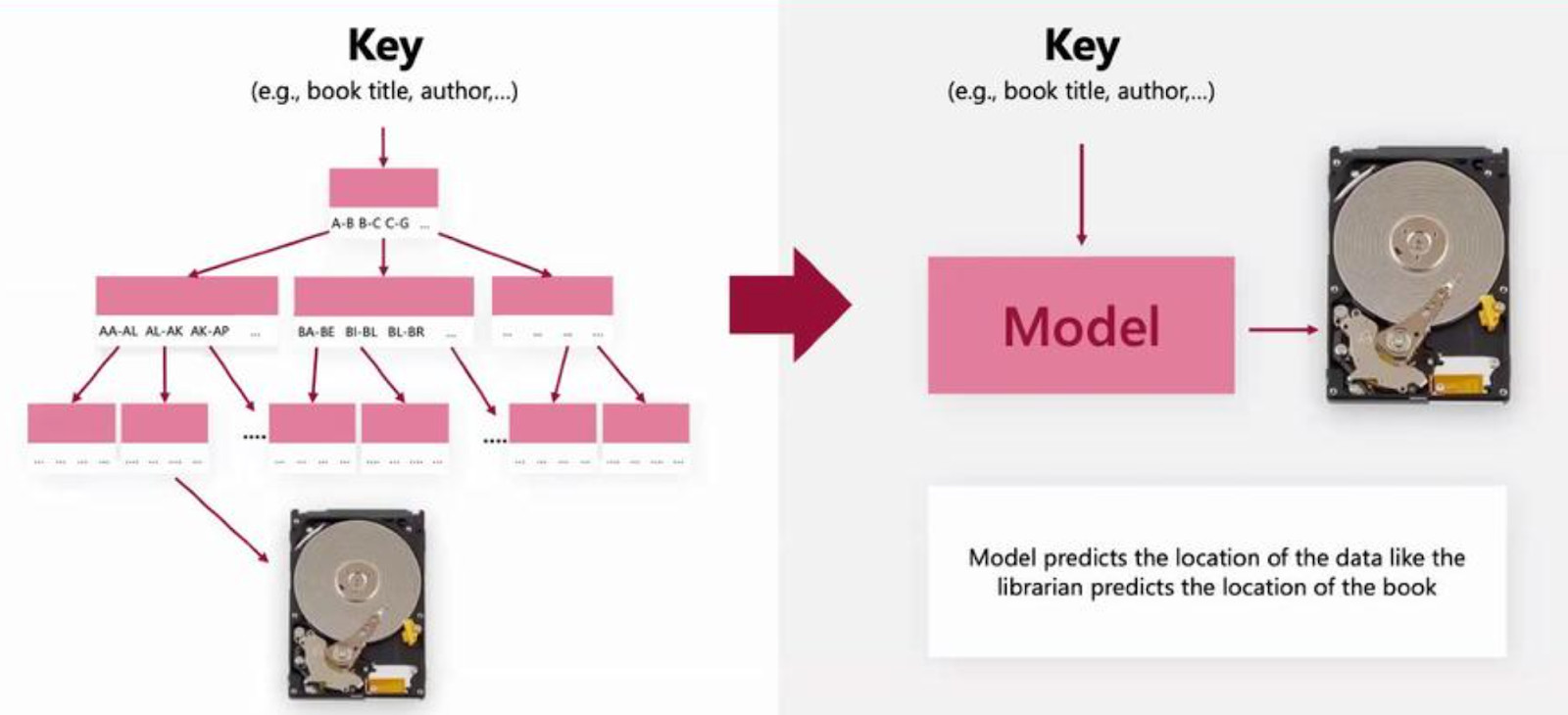
The context of learned indexes is to work with sorted indexes. How can you find where the row you want is, based on an index?
The naive solution is to search the desired index from the list of all indexes: is the index above this one? If yes, look at the next one.
Many database tools use a variation of b-trees that can get you the position of the index by doing a search in a tree and drastically reducing the number of comparisons.
This solution is very efficient and generalizes well but it misses obvious opportunities. If all indexes are subsequent the value to row number is just a linear operation!
To a larger extent, if you could construct a cumulative index function, you could have a data-driven index mapping. Get an approximate row number from the index function, and then search thoroughly around its neighborhood.
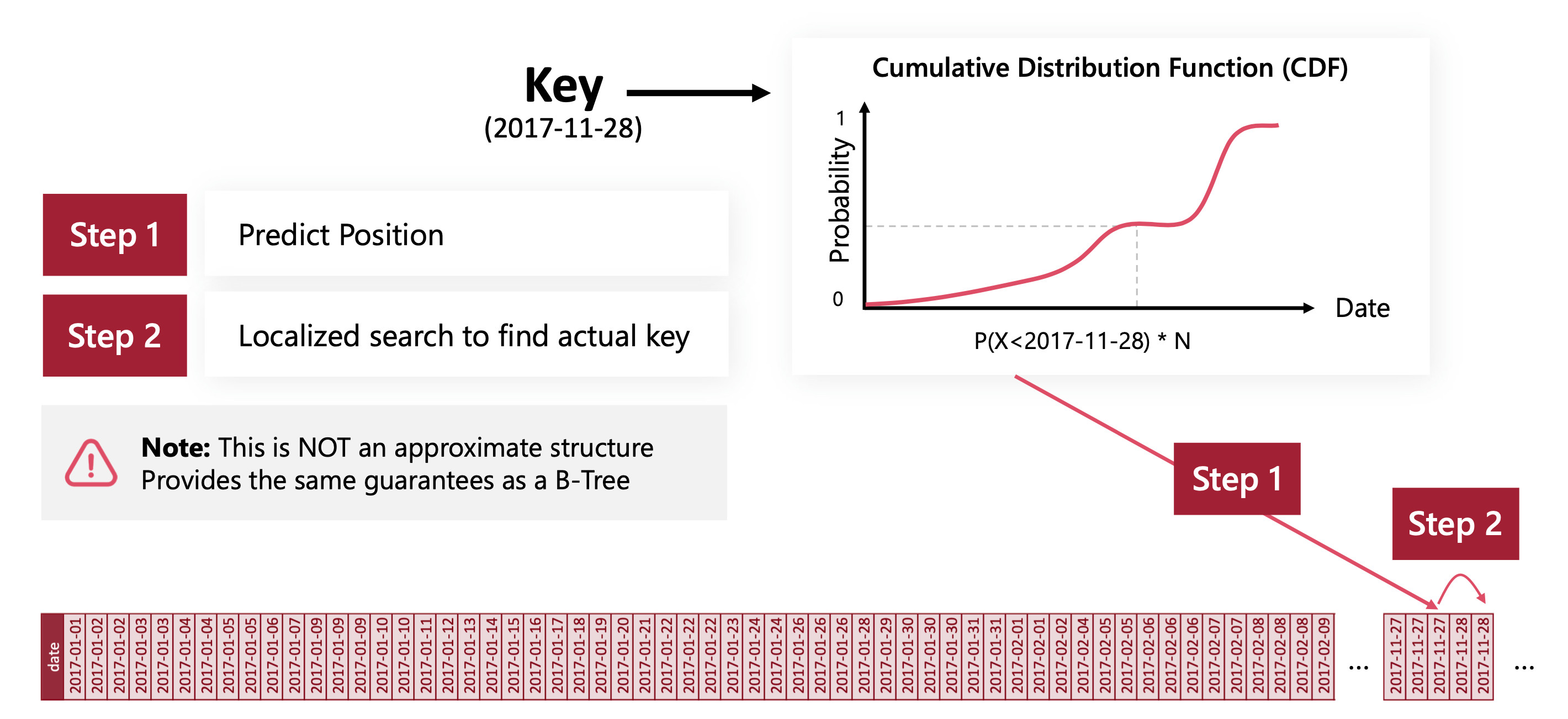
Learned indexes is thus a generalization of this technique. The cumulative index function is traded for a neural network that tries to perform the same mapping.
The system is not suited for real world usage as is, especially since the only scope is reading speed. Updating the index is the weakness of learned indexes.
When you update your database by writing new entries, you might have to retrain this learned index, and this requires loading the whole index, which induces very high I/O costs. To be considered mature and up to real world standards, the cost of updating the model and storing incoming data needs to be drastically lowered.
However, this technology is very promising. The first time this work was presented, it triggered lots of discussion (both good and bad reviews).
The concept of learned index is now a very active research field with more than 50 papers trying to improve it. Among them we can cite Piecewise Geometric Model (PGM) which is a fairly convincing attempt at making both index update and retrieval very fast and cheap. Instead of a cumulative distribution function, the proposed solution models the index/position mapping with a piecewise linear function, which is easier and faster to update than a full Machine Learning model.
See Learned indexes implemented on GitHub.
Grid pattern databases
This is about filtering the data on a specific interval. For example you want to select people with an age between 40 and 50. The way to arrange storage in order to optimize this query is to sort by the mentioned column (age). You will then only have two indexing operations to perform, you can even use learned indexes for that.
The problem arises when you want multidimensional conditions. What if you are searching for multiple axes at the same time? You now not only want people with an age between 40 and 50, but also a salary between 80K and 100K. You won’t be able to optimize both conditions easily.
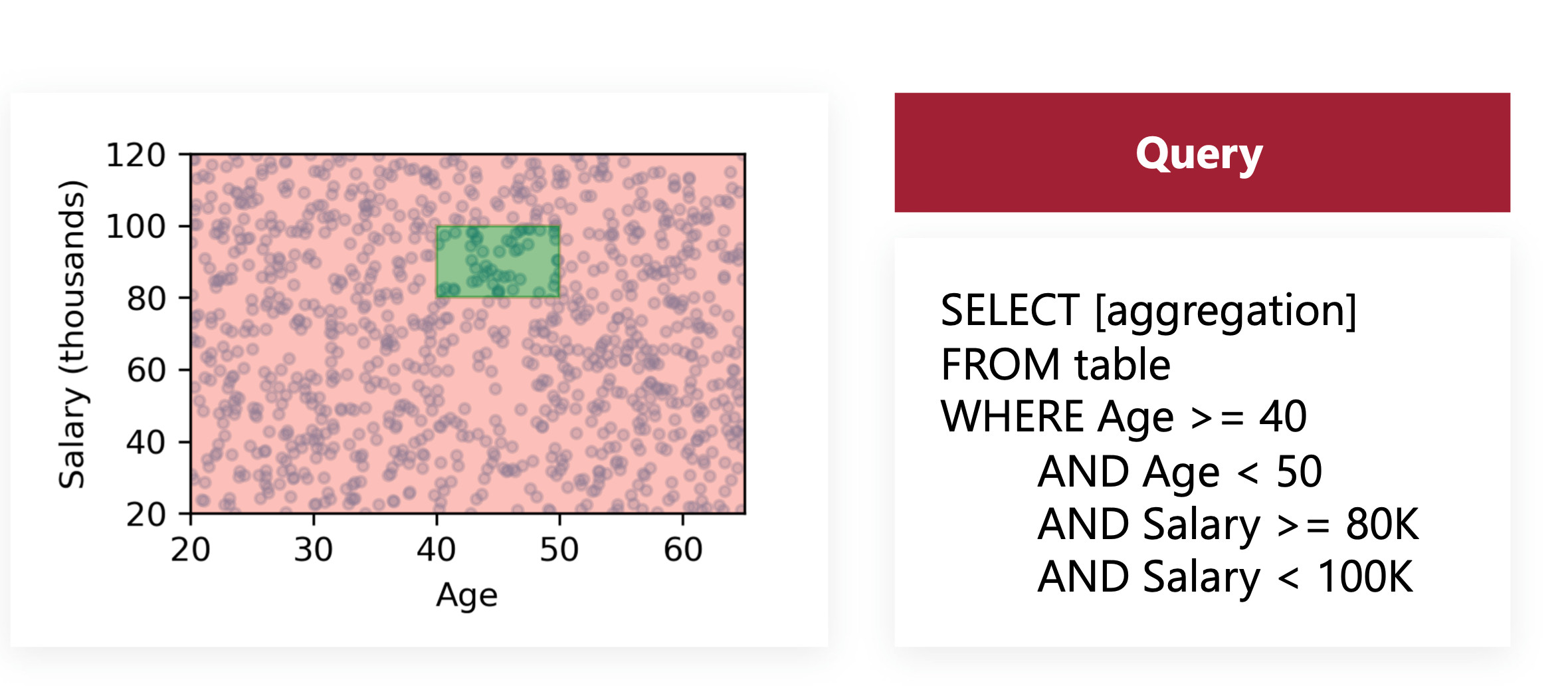
The proposed solution consists in reasoning with grids. Instead of sorting only one value, you sort and interlace N values together. The strategy with the given example is to group together data points with Age and Salary within the same intervals. Now inside these two intervals you can do a thorough search for the values you want.
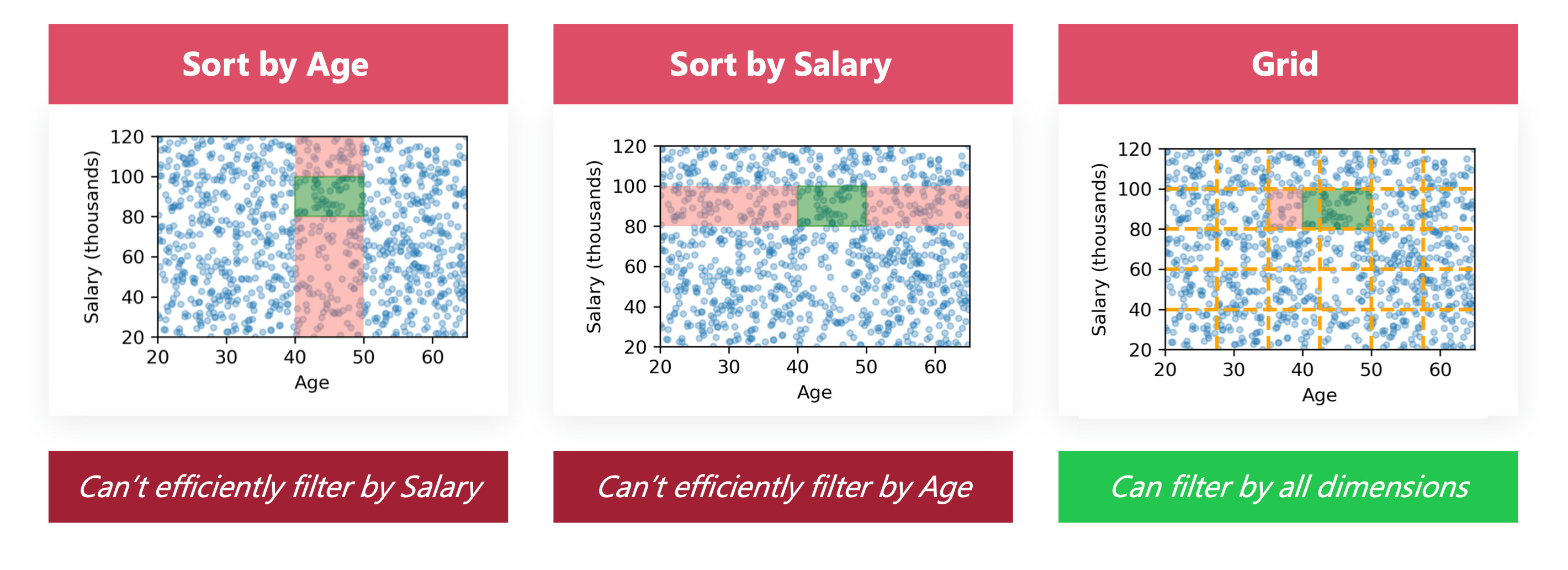
The query can then be divided into two steps:
- Search for the grid cells your data range is included in
- Search inside the cells in the regular fashion, with one axis that is sorted
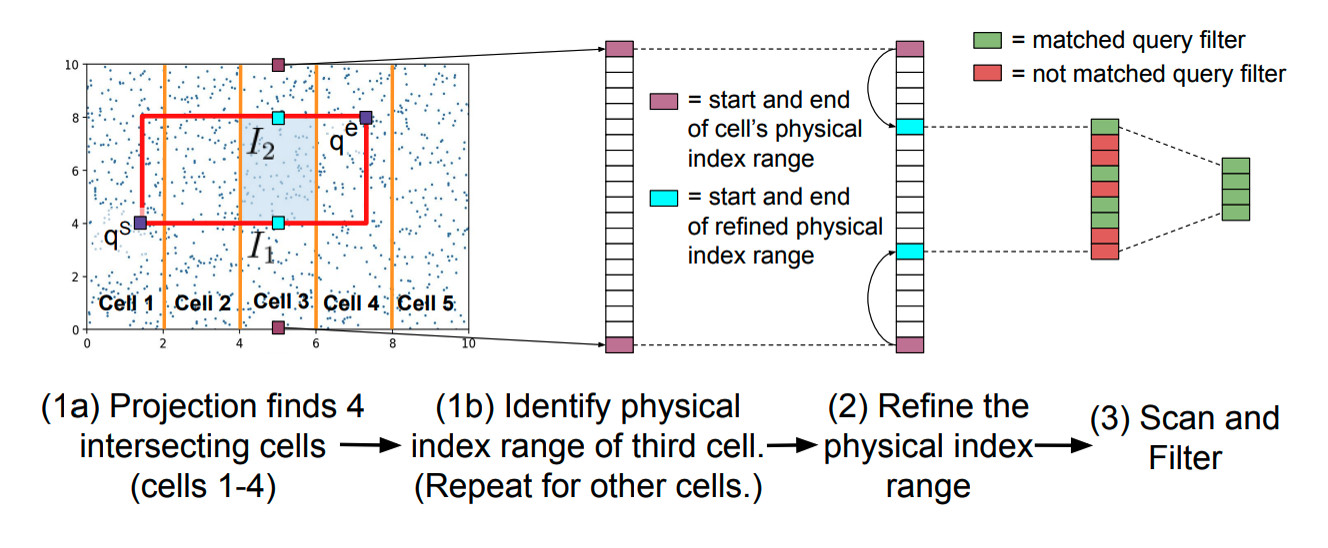
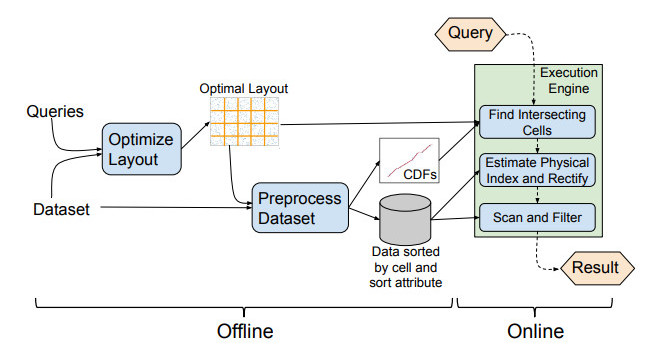
What about the general case then? Can we automatically set up a grid layout based on our typical queries?
This is where the Flood technique shines: from the former queries, the grid layout is optimized so that next queries will be even faster. The database index is then regularly updated in its storage layout for faster queries, based on past queries, provided that the next ones will follow the same pattern.
Of course this update is not free at all since it requires copying the whole database index in another grid layout.
Again, this work, although promising, should be regarded as still very theoretical because there is no clear strategy on how to support insertions efficiently. Nevertheless, this paves the way for an adaptive grid layout that would have better reading performance than most classical indexes.
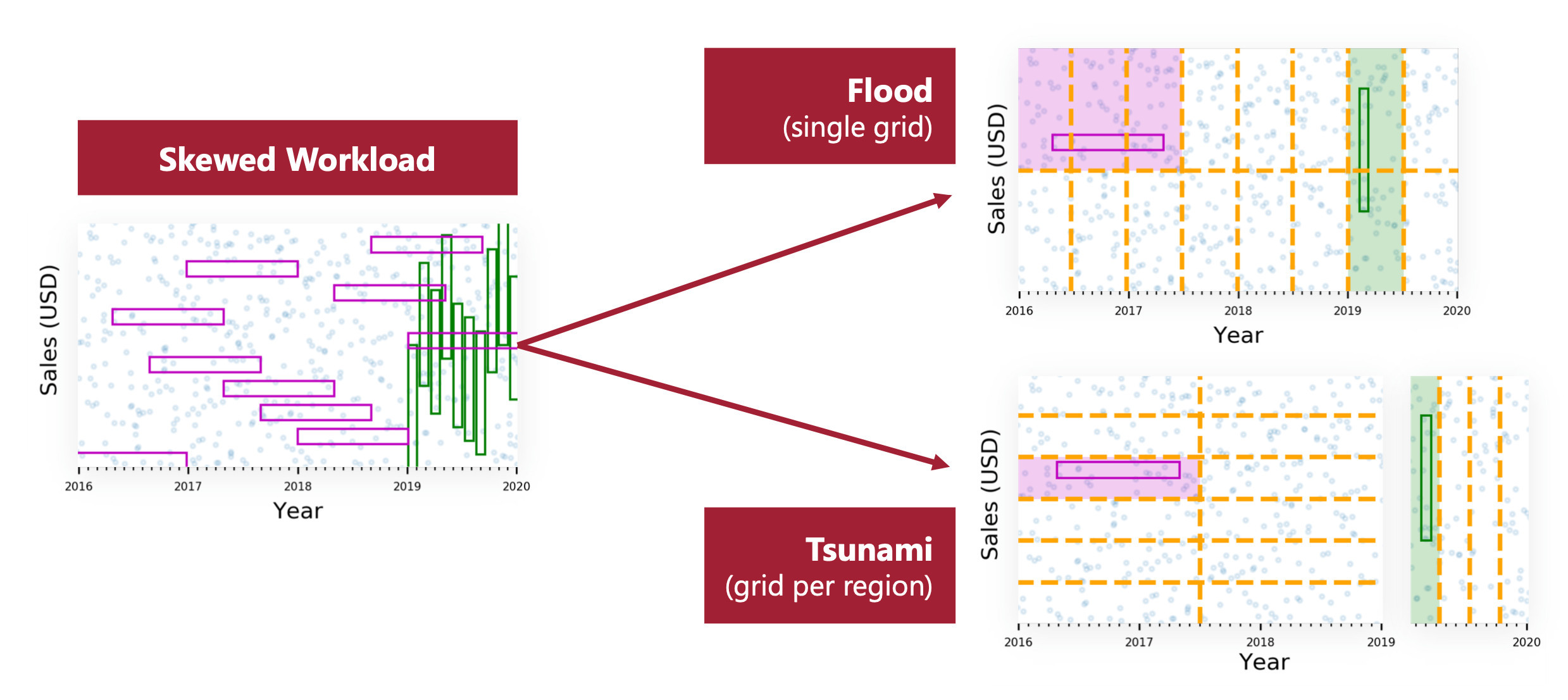
We can go even further by trying to have an adaptive grid if our queries don’t follow only one pattern.
Imagine that for higher salaries, the Salary range is bigger and the Age range is smaller. Maybe for this part of the database, it’s better to change the shape of the grid, or even the primary dimension of the grid. This means that even though we are using the same kind of data, the optimal grid pattern may change with a different range of Ages and Salaries.
The Tsunami technique builds upon Flood to offer an adaptive grid layout, which now not only optimizes on query patterns, but also on query location in the database. In addition to Flood, Tsunami identifies pattern discrepancies and is able to leverage it so that each location in the database has an optimal grid, and not only a single grid that would be average everywhere.
SQL Optimizer
The last Machine Learning tool that was presented was the SQL Optimizer. Most SQL optimizers only follow a selection of common heuristics that work most of the time. The question is then how do you optimize your SQL optimizer? The only solution is to run a few benchmarks, propose some hand crafted improvements and assume that the dataset used for the benchmark is representative enough for all future use cases. The main problems of this approach are:
- Your dataset will not be specific enough. Most of the time, the optimization task is not done by the user but by the database maintainers, which means they try to find a good compromise to have reasonable performance over every possible use case of the database.
- There is no direct feedback loop, the optimizer has no way to understand that it might be wrong sometime when in real use. If the dataset used for benchmark is not very representative of a particular use case of a specific user, there is no way to be aware of that.
SQL online optimizers such as NEO try to address this problem by learning and optimizing directly from the end user data. The SQL optimizer will then be custom tailored for each real use case. This optimizer uses a famous reinforcement learning (RL) technique, called Value Iteration.
The goal is to have two models:
- The Value model, will try to predict the outcome (the processing time) of a proposed action (the query plan).
- The Policy model, will optimize the first value model by proposing the best query plan.
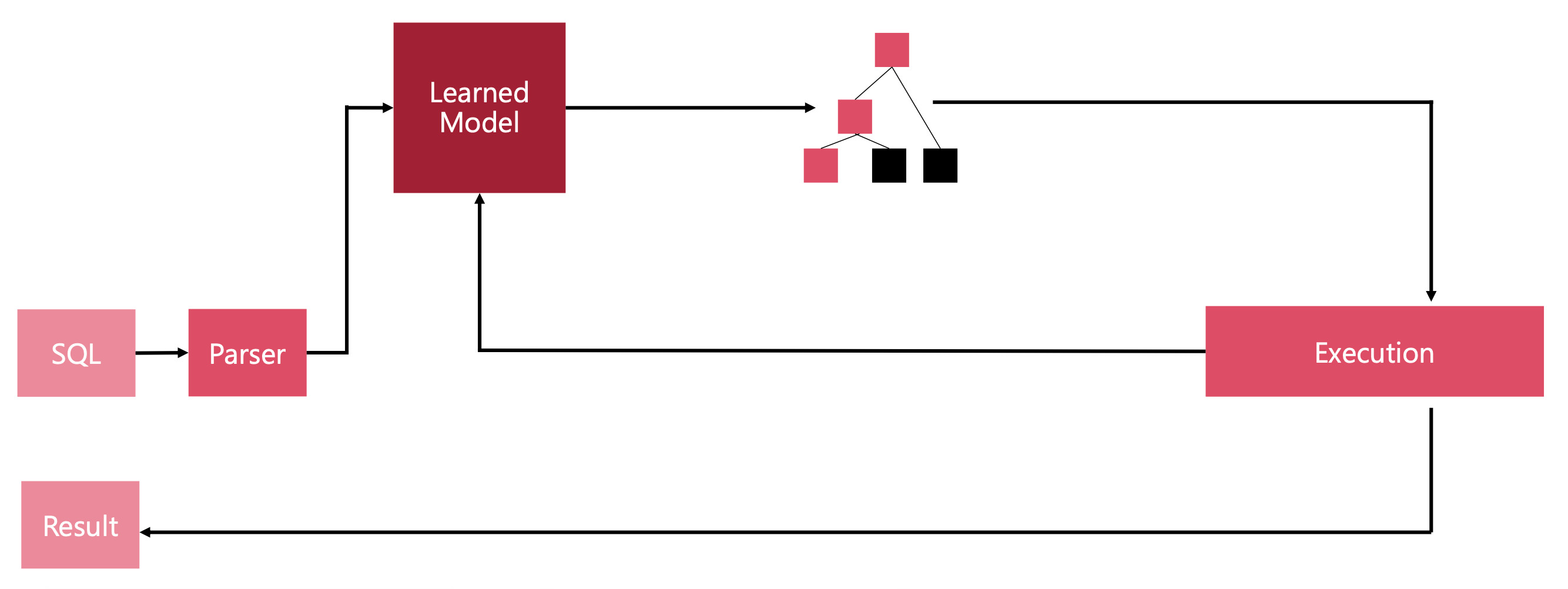
Now even though this system works in theory and had good experimental results, the adoption is heavily mitigated because of the following reasons:
- No explainability. The decisions taken by the algorithm are hard to understand, which means the human is completely out of the loop and has to blindly trust the optimizer.
- No convergence guarantees. Reinforcement Learning techniques are notoriously sampling inefficient and unstable. It takes a very large number of queries to be finally better than traditional optimizers, and training is not guaranteed to converge every time.
- No robustness guarantees. As every Machine Learning method, the trained model will only be as good as the data it was trained on. In other words, if the training set is not representative enough of the real world, the trained model won’t be robust to unseen edge cases.
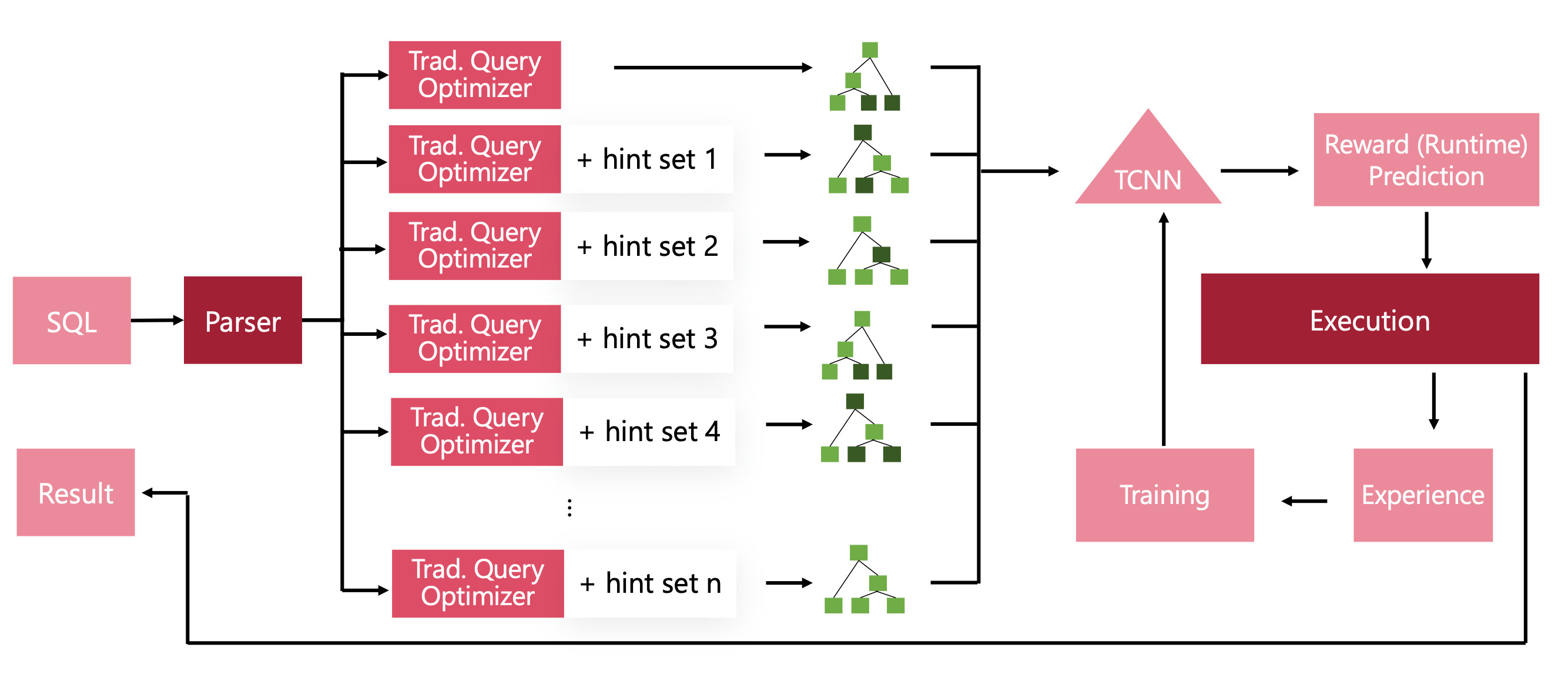
To address these issues, BAO was introduced.
Instead of having a model to generate a query plan completely, it starts from a collection of different SQL optimizers. Each optimizer is a variation of the base Query optimizer, and some additional hints.
For example, the cardinality estimator might be more or less pessimistic when predicting how many rows will be included within a particular condition regarding Salaries, because it will assume that the distribution of Salary values have a great density.
As a consequence, this particular SQL optimizer will prioritize applying a filter on Salary values first to apply other aggregation or condition tasks on less data. The BAO optimizer is then a way to choose the best SQL optimizer that fit for the incoming query.
This technique allows us to understand why the optimizer acts the way it does. The hard to understand decisions now rely on the choice of optimizer. It also constrains the universe of possible SQL optimization strategies to the set we manually constructed beforehand, guaranteeing the robustness to edge cases.
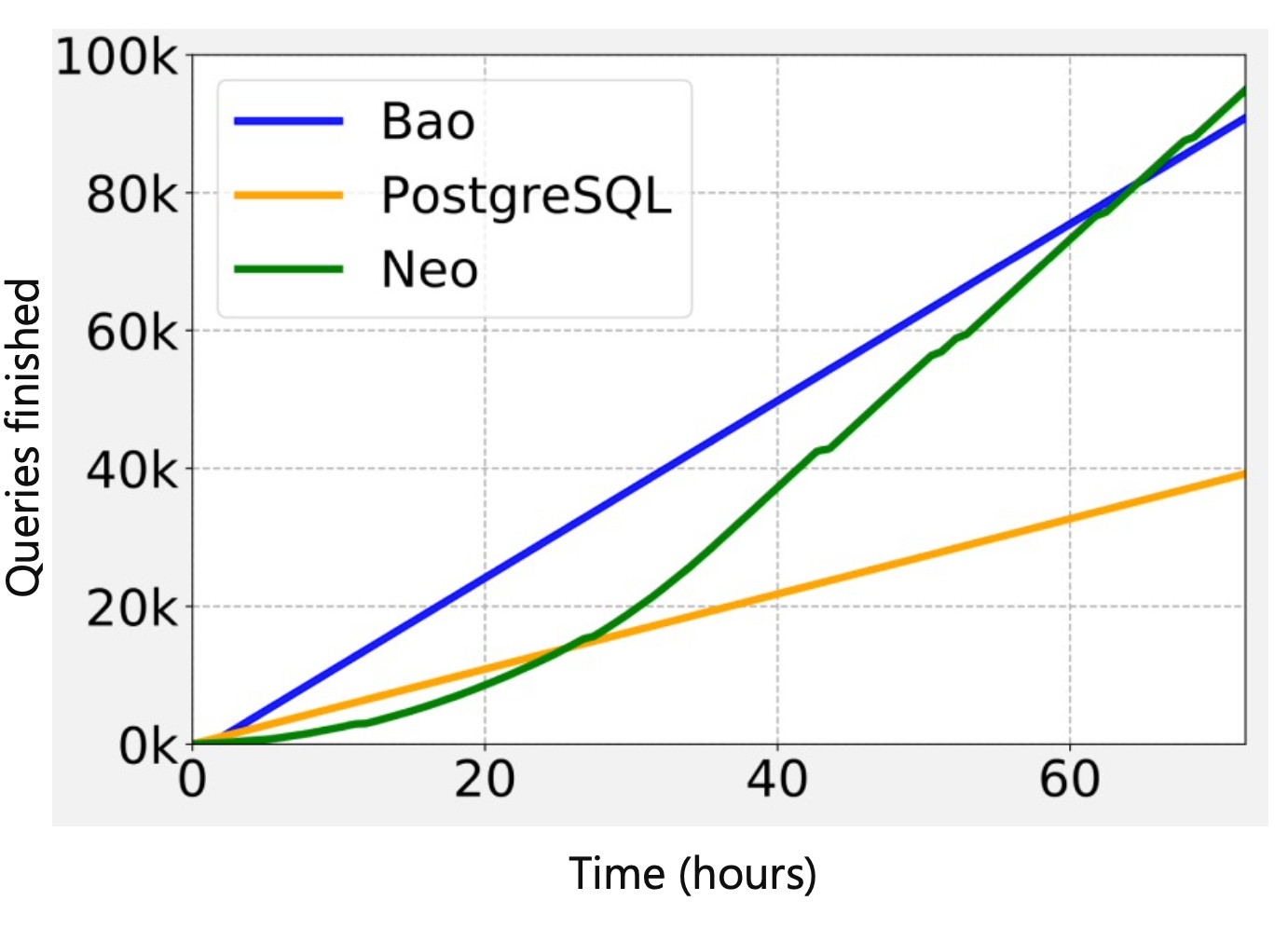
The benchmark then shows some unsurprising results, where BAO gets better results in the beginning, thanks to the collection of optimizers it comprises. But it gets beaten by NEO in the long run.
SageDB, an open source project that you can delve deep in
As said above, these three techniques were cherry picked among a set of tools that were developed in the context of the broader project called SageDB. If you found the three aforementioned tools interesting, you should definitely check this project out.
On a final note, Tim’s team is uploading most of their work on GitHub, as well as the benchmark suite they used in their experiments so you can try to build upon their solutions. Kudos to them for open sourcing science!
Not yet used in production
SageDB seems to be a very promising technology. It allows you to leverage on patterns in your database from the way it is stored to the queries you usually do.
At Contentsquare, we keep an eye on any innovative database, to keep ahead of our future needs. SageDB is full of great ideas, but is still too experimental for us to use in our production pipeline.
The maturity and stability of a database technology is often the most important aspect, to reduce the cost of being wrong. The way most database technologies work is to be very robust to edge cases and even though they may not be the most efficient for some data with a special pattern, they will offer a decent minimum performance with it.
With specialization comes the lack of flexibility and robustness. It is certain that with time, SageDB and other Machine Learning based database technologies will become more and more robust.
For example, Google’s BigTable is using Machine Learning for key-value pairing, in a similar fashion than learned indexes, Microsoft is using BAO on some of their big data projects.
We will keep following research trends on databases carefully and can’t wait for SageDB to mature enough for us to start some experiments!
Sources and references
- The Case for Learned Index Structures, by Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, Neoklis Polyzotis
- Why Are Learned Indexes So Effective?, by Paolo Ferragina, Fabrizio Lillo, Giorgio Vinciguerra Proceedings of the 37th International Conference on Machine Learning
- Learning Multi-dimensional Indexes, by Vikram Nathan, Jialin Ding, Mohammad Alizadeh, Tim Kraska
- Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads, by Jialin Ding, Vikram Nathan, Mohammad Alizadeh, Tim Kraska
- Neo: A Learned Query Optimizer, by Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Papaemmanouil, Nesime Tatbu
- Bao: Making Learned Query Optimization Practical, by Ryan Marcus, Parimarjan Negi, Hongzi Mao, Nesime Tatbul, Mohammad Alizadeh, Tim Kraska