Fighting bias in Machine Learning
As Jenny Davis, sociologist and keynote speaker of the 2022 ICLR conference pointed out, technologies are social, political and power infused. This is the starting point and core issue of a growing research topic: ethics in technology. Because technologies reflect and shape norms, values and patterns, they cannot be seen merely as tools. Being aware of the social impact of the technologies we are creating is the first step towards a more responsible research and innovation.
We are focusing here on a specific technological field: Machine Learning (ML). ML reproduces and amplifies social inequalities. “Reproduces” because ML systems use data from people who live in an unequal society; “amplifies” because a single ML model can impact millions of people at once. Bias in ML was a significant aspect of ICLR, in which researchers from various fields came together to answer questions such as: “how can we spot bias within our data and our models?”,“what are the different biases in ML and how can we mitigate them?”.
As an illustration of bias in ML, let’s take a specific example: COMPAS.
COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) is a commonly used algorithm for decision making in the US criminal justice system. This algorithm assesses the likelihood of a defendant becoming a recidivist. It uses data collected from criminal records and from questions directly asked to the defendants, such as “was one of your parents ever sent to jail or prison?” or “how often did you get in fights while at school?”. The algorithm then produces a score which indicates the defendant’s risk of future crime.
In 2016, a ProPublica investigation of the algorithm shed light on the bias of the algorithm against blacks. Even though the race of the offender is not asked in the questionnaire, the team analysed the risk scores within a population and discovered that “blacks are almost twice as likely as whites to be labeled a higher risk but not actually re-offend,” whereas COMPAS “makes the opposite mistake among whites: they are much more likely than blacks to be labeled lower-risk but go on to commit other crimes”.
This example (among many others) raises the question of the responsibility we have as scientists on the social implications of the technologies we build. Do we want to represent society as it is or do we want to aim towards a more equal and fair society through our models?
What kind of bias?
Bias affects any ML project with a social impact. The bias in the COMPAS algorithm mentioned above is clearly acknowledged but sometimes bias can be more subtle.
The first step is to recognize bias in our perception and our environment, due to our own social and cultural identity. This human bias is then propagated through the whole ML pipeline, from data collection to modelisation, and it is crucial that we consider every kind of bias we encounter within our ML projects.
When we hear about bias in ML, we think about bias in data. But would unbiased data be sufficient for unbiased ML?
In their paper Bias in Machine Learning - what is it good for?, Höllstrom et al. present an interesting taxonomy of bias in the ML pipeline.
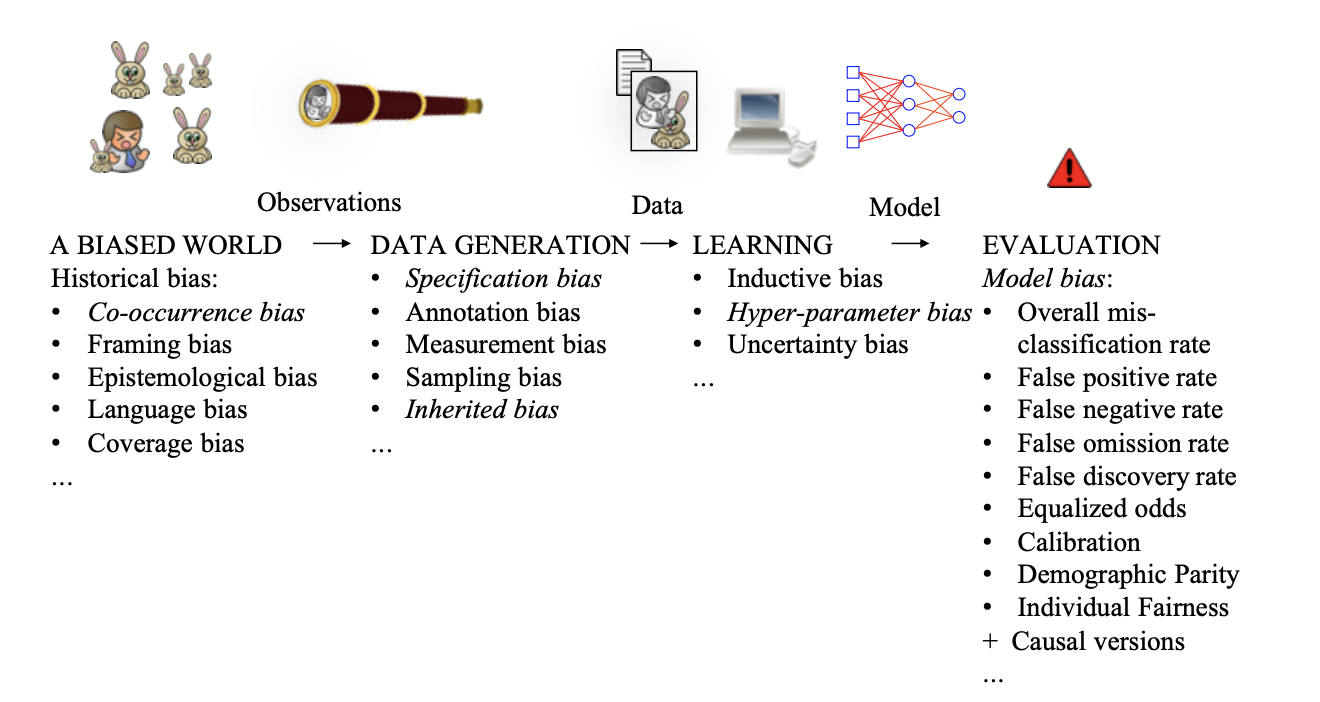
We can see that all aspects of an ML pipeline, from observations to model evaluation, are subject to numerous biases. Imagine bias in ML like a layered cake, each layer building off of each other.
A biased world
First and foremost, the foundation of the cake is the biased world we live in. Therefore, when fetching data from any source, we are undeniably faced with conscious or unconscious biases. The hardest to detect is the framing bias, which refers to the fact that the way a problem is stated can influence the way we answer it. Similarly, the way data is represented can influence the decision making. A commonly used example to illustrate this bias is an ML model that is designed to classify men and women from pictures. As the training data contains more pictures of women shopping or cooking than men doing these activities, the model is likely to infer that a picture of a man in a kitchen represents a woman.
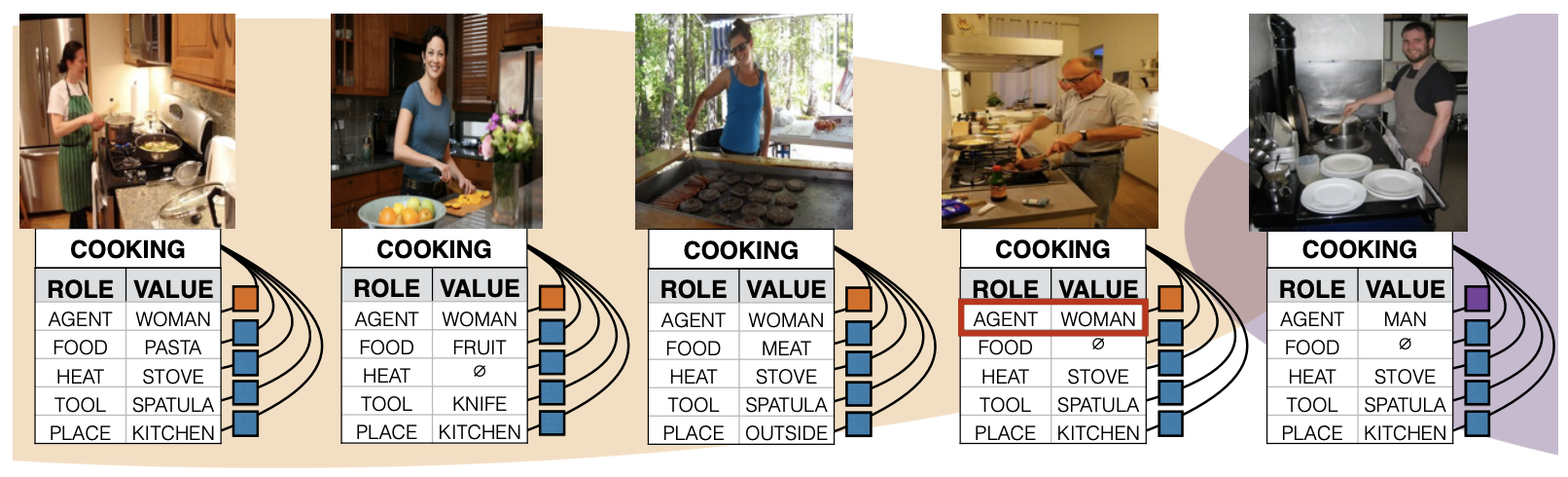
Source: Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints
Bias in data
The second layer is bias in the data itself. The designer of the model will take multiple decisions regarding data collection and generation. Choosing the kind of data that is best-suited for their goal and the features to extract from it is subject to bias. For example, choosing “number of arrests of family or friends” as a feature in the COMPAS algorithm, knowing that arrests are more common among blacks than whites, could be discussed. Then, sampling the data can lead to bias when some members of a population are systematically more likely to be selected in a sample than others. That sampling bias can have disastrous consequences in the medical field. For example, an algorithm trained with mainly images of white skin to detect skin cancer is likely to misdiagnose people with darker skin. Finally, labeling data - manually annotating each sample of the dataset - inherits human bias as well.
Bias in models
The third layer is the bias in the learning phase. The choice of the model, the objective function, the hyperparameters, etc, are not inconsequential. What is usually observed is an anchoring bias, meaning that we tend to choose models we are most familiar with, with no further thought, and a default bias: choose all default values for hyperparameters. Take the learning rate in neural networks: this parameter controls how much the weights are adjusted in the neural network based on the minimisation of a loss function. While studying the behavior of different neural network optimisers on unbalanced data, Z. Jiang, et al. showed in their paper that underrepresented features are learnt later in the training. Thus, choosing a high learning rate - which means stopping the learning process early - will negatively impact the model performance on an underrepresented subset of the population.
Bias in evaluation
The top layer of the cake is the bias in evaluation. On the one hand, we usually face what is called a congruence bias. It is the tendency of people to over-rely on testing their initial hypothesis while neglecting to test alternative ones. On the other hand, the benchmark dataset we use to evaluate our model against, might be biased in the first place! That is essentially the risk of the feedback loop: data created from models are used to evaluate other models, which amplifies the bias issue.
Our metaphorical cake already has 4 layers of bias, but if you want to go further, you can read about the 23 different types of bias in ML.
How to evaluate bias?
There are some standard indicators we can use to evaluate bias in data and ML models. They aim at assessing whether the ground truth or the model predictions differ significantly among groups with different values in protected attributes, such as gender, race, religion, etc.
Let’s consider a binary classifier, against a protected attribute . Let’s denote the ground truth, and the prediction. Three indicators we can use to quantify bias are:
- Demographic parity (or calibration): it assesses if the proportion of people that are positive in a population is equal to the proportion of people that are positive in each subgroup of the population.
- Statistical Parity Difference (SPD): it measures the difference between the probability of positive outcomes across the groups of the protected attribute:
- Equal Opportunity Difference (EOD): it quantifies the discrepancy between the True Positive Rate within the groups:
For example, if A represents gender, the fact that a person is a man should not increase or decrease the chance of a positive prediction (SPD), or the chance of being well classified (EOD). We can use similar formulas for other classification rates such as false positive rate, false omission rate, etc.
Each of those metrics define one specific bias measure. Therefore, debiasing data by minimising SPD or EOD for example does not imply unbiased data, but unbiased (or less biased) data in regards to a certain metric.
How to reduce bias?
On a conceptual level, ML can be more socially responsible if built through systemic frameworks. One of the keynote speakers of ICLR, the sociologist Jenny Davis, author of the book “How Artifacts Afford: The Power and Politics of Everyday Things” (MIT Press 2020), explained how a critical analysis and (re-)design of a system can be used to build better ML. The main idea when building a model is to not only answer the question “what is the technical/business purpose of the system?”, but other analytical questions such as “what are the social outcomes?”, “who does it impact and how?”, as well as design related questions such as “how do we make systems that encourage dignity, refuse exploitation, discourage power asymmetries?”, “what features obstruct these goals and how might they be remade?”, “how do we want these data inputs and outputs to operate?”.
Jenny Davis mentioned that this is a continuous process, especially when dealing with dynamic systems such as ML models. Because models are responding to a dynamic social world that has and continues to reflect, perpetuate and intensify unequal social relations, analysis and (re-)design are inextricable; analysis should be done with an aim towards re-making, adapting and sometimes dismantling models.
On a technical level, eliminating bias from AI systems is often considered impossible, but we can try to mitigate it. A large variety of techniques have been developed to serve that purpose. Here is a taxonomy of those methods within the ML model life cycle.
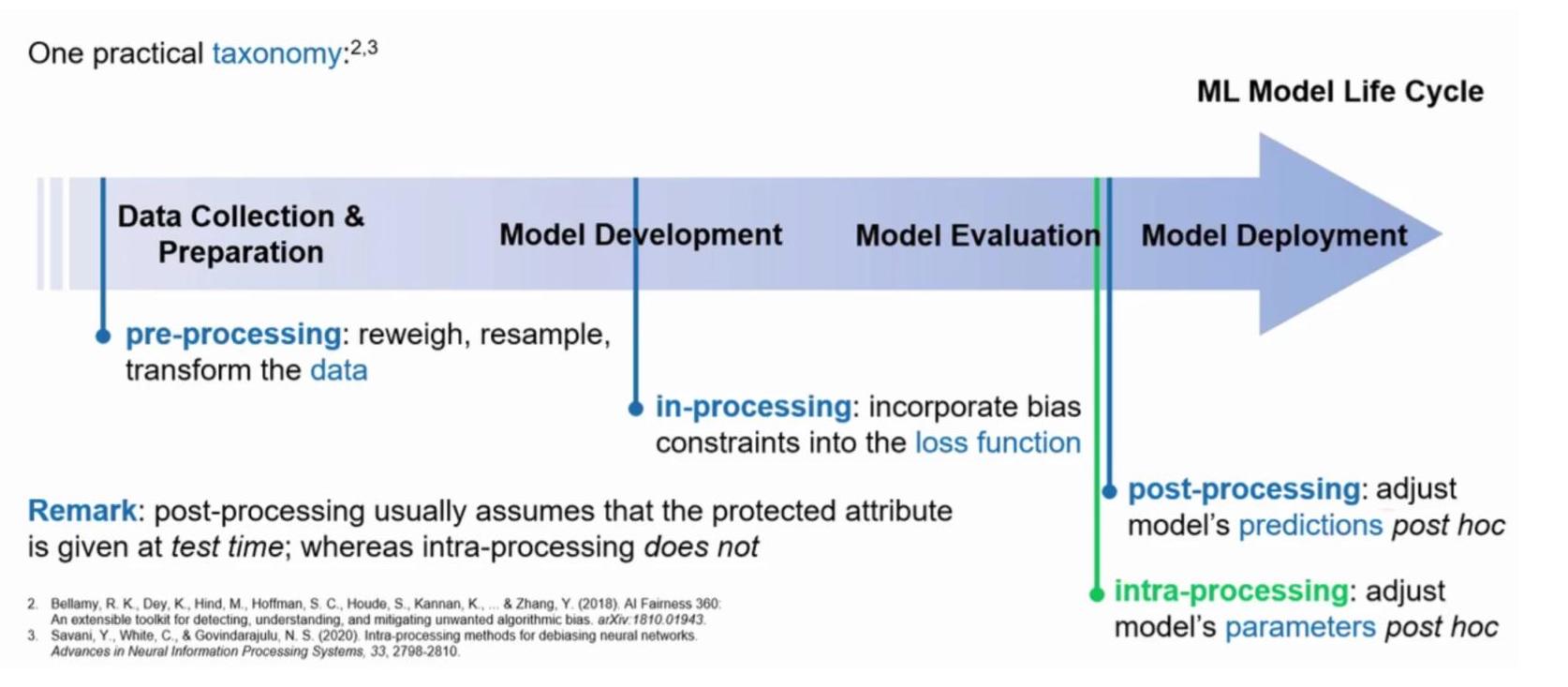
Source: ICLR 2022 workshop “Socially Responsible Machine Learning”, Ričards Marcinkevičs presenting the paper Debiasing Neural Networks using Differentiable Classification Parity Proxies.
Pre-processing methods
Pre-processing methods aim at debiasing the data itself. In a case of an imbalanced dataset, sampling or reweighting data can be used to obtain a better representation of the under-represented groups, and thus give the models a better learning opportunity. Additionally, removing the protected attribute (gender, race,…) from the features seems to be an obvious way to reduce the bias in the data. However, it is not always the case, as the proxy features may contain historical (cultural) bias: the COMPAS algorithm for example, was biassed against blacks even though race was not a feature. Sometimes, changing the labels of the training data can be an adequate solution. Let’s take the example of an algorithm designed to automatically select candidates based on CVs. The algorithm will look for schools or relevant experience. But what if two candidates with the same exact features, who differ only from their gender, have different labels: one is hired, the other one is not. The model will then struggle to make a decision on similar profiles. Changing the label in that case might overcome the issue. In their paper, Data preprocessing techniques for classification without discrimination, Kamiran and Calders present those interesting approaches.
Post-processing methods
Post-processing methods treat the biassed model as a black box and merely edit its predictions. The most common approaches use the Equalised Odds and the Reject Option Classification (ROC). Equalised Odds requires that the True Positive Rate and False Positive Rate are equal among all the groups. Thus, the predictions are changed based on the optimisation of those functions. Instead of assigning the label with the highest probability, ROC defines a “blurry region” - where the class probabilities are close - selects the people from the positive privileged group and the ones from the negative underprivileged group inside that region, and changes their prediction to the complementary one. In the paper Decision theory for discrimination-aware classification, Kamiran et al. explain the method and show positive outcomes.
In-processing methods
In-processing methods incorporate fairness constraints in the model itself. It can be done by adding a regularisation term or a constraint function such as SDP or EOD to the objective function, or an adversarial loss to the model loss function.
Intra-processing methods
Intra-processing methods are fairly recent. They fine-tune and change the model’s parameters post-hoc. The main advantage of those methods compared to in-processing ones is that they do not rely on the training data. Thus, if a model is developed using a certain dataset, without any knowledge of a potential bias, and we want to deploy the same model to another dataset, with local fairness considerations and constraints, we would only need the model’s parameters to debias the model, not the full training set.
Conclusion
We live in a biased world. The prejudices that we carry are transferred into the technologies we build. To build a more socially responsible ML, we need to see further than our practical or business goal. The first step is to scrutinise our data, our models, and check for potential harmful bias. On a quantitative perspective, we can measure fairness on multiple levels and use various techniques to try minimising bias without compromising on the accuracy. We often don’t have the keys to assess, predict or understand the social impact on smaller and less represented social groups. Thus, collaborating with people from different backgrounds and perspectives is valuable. May we build models through a critical lens, held in many and diverse hands!
Many thanks to Tim Carry, Mohammad Reza Loghmani, Sharone Dayan and Sihem Abdoun for their reviews!